



One of the Microsoft Fabric user experiences is Synapse Data Science, which provides the ability to create machine learning models, register them in a Fabric workspace, and integrate them with the rest of the Fabric features, such as Delta Lake tables and Power BI.
In this post I'll show you how to use Jupyter Notebooks in Fabric. I'll focus on moving an existing notebook from a local Anaconda environment into the Cloud-based Fabric workspace, since that's the path many new Fabric users will be following.
Video walk-through
This post is also available as a video walk-through on YouTube! The text version of the walk-through continues after the embedded video.
The Data Source
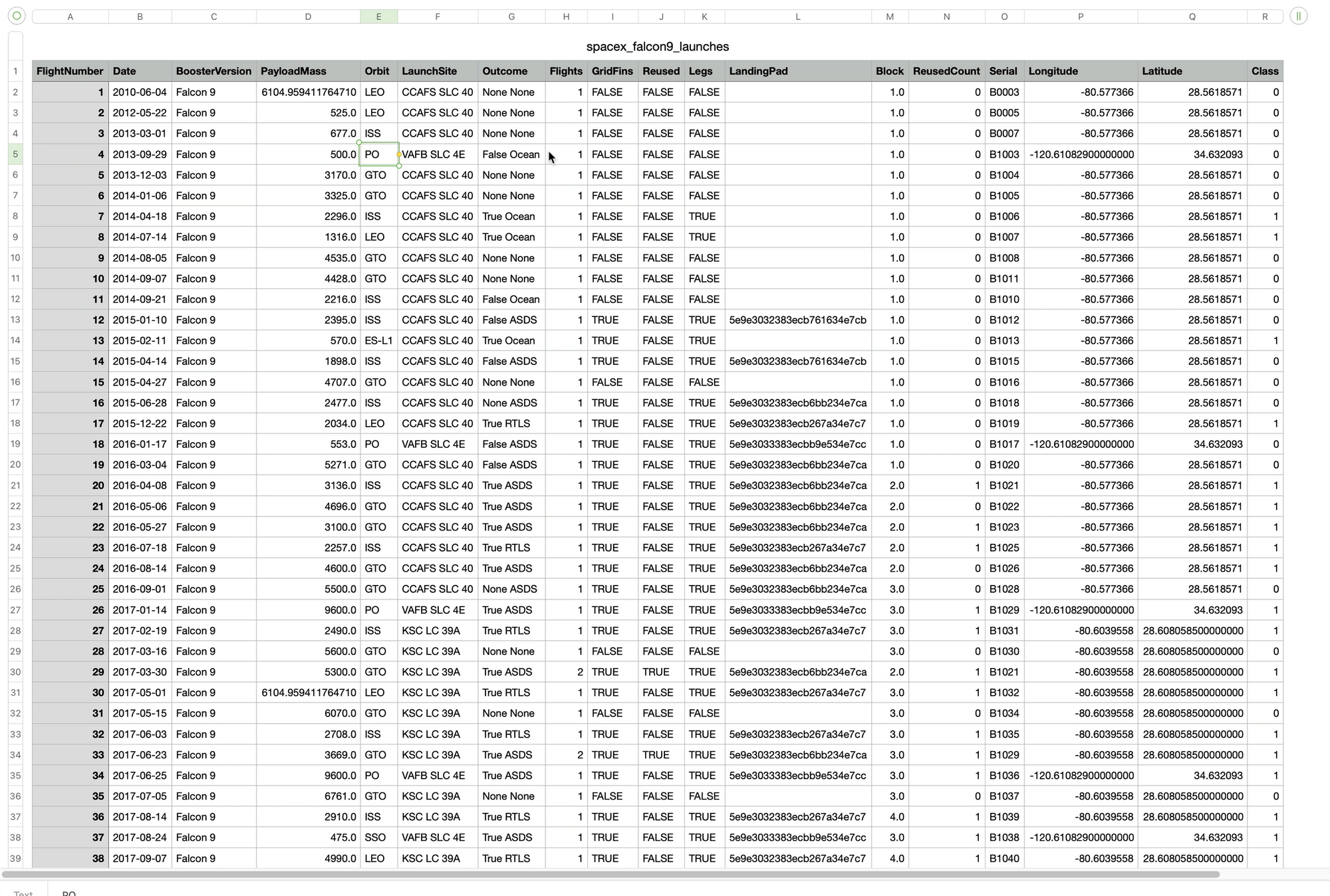
The data source I'm using is a table of SpaceX Falcon 9 launches. The data shows each launch, various metrics, such as the payload weight, which rocket was used, etc. The target variable is whether the launch was successful or not. The machine learning model will be trained to predict the success of future launches based on these input variables.
Local Jupyter Notebook
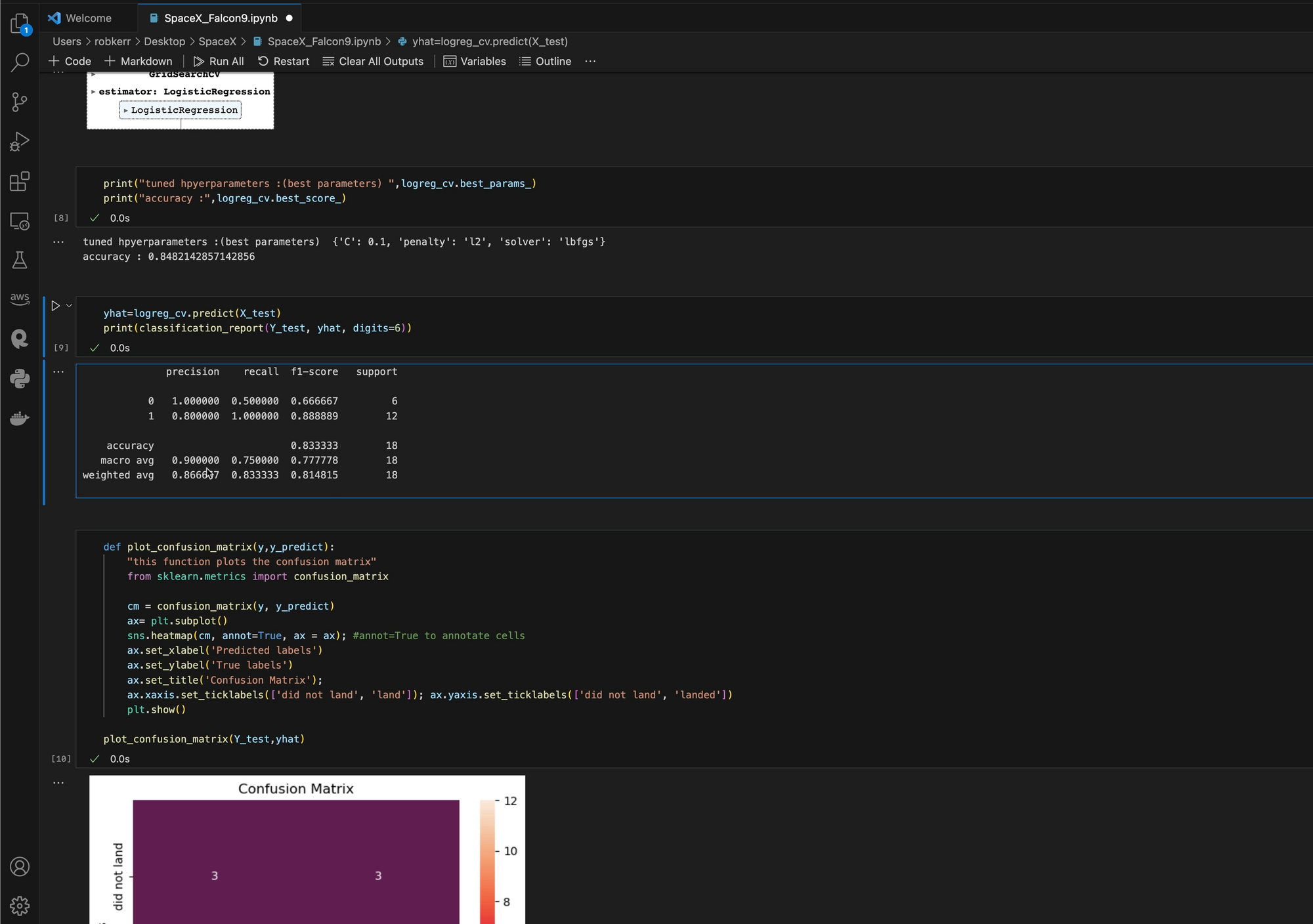
Often Data Scientists use Anaconda and Jupyter on their local computers, and that's how I designed this solution. I'm using Visual Studio Code with an Anaconda kernel on a local machine.
Given the small data size and simplicity of the model, I'm not pushing the limits of my local machine at all--but when the data size was larger, or compute needs grow, local training and data wrangling can become more challenging!
Migrating the Solution to Fabric
Fabric fully supports Jupyter notebooks, including all the dependencies I used: Scikit-learn, Seaborn, Numpy and Pandas. Uploading the data and notebook to Fabric for cloud processing is quite straightforward!
Upload the Data File
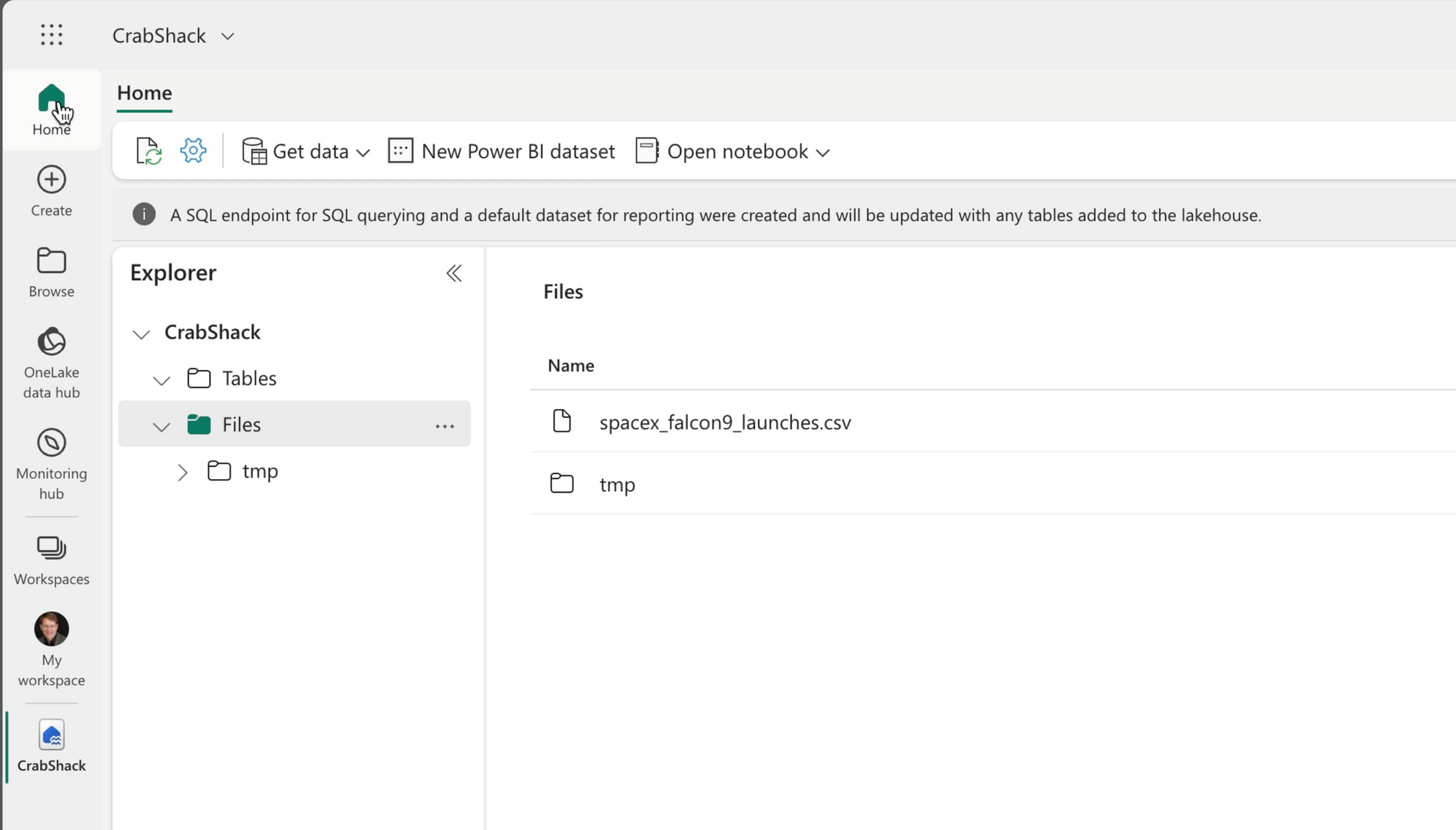
The existing Jupyter notebook fetches data from an Azure blob container--and while I could continue to do this, I chose to import the .csv file into the file folder of my Fabric Lakehouse.
With a small file, this is as easy as uploading the file from desktop to cloud. The advantage of placing this file in the Lakehouse is that anyone on my team could easily find it and include it in their notebooks or import it into other Fabric solutions.
Upload the Notebook
Uploading the Jupyter notebook is also very simple. No changes are needed to the Anaconda notebook to run it in Fabric. I simply upload it to my workspace in Fabric, and then open it up.
Change the Data Source
Since I want to use the Lakehouse version of my SpaceX input data, I need to change the notebook to fetch the CSV file from that location rather than the Azure blob container.
This is the only change needed to the notebook to support this simple "lift and shift" migration of a model training notebook.
Run the Notebook
Once the data source is updated, I can just run the notebook as usual.
One of the differences from using the local Anaconda solution is that Fabric will run the job on an Apache Spark cluster--which can scale as large as needed to efficiently run very large data and compute workloads.
While on a small 90-row file like this one, the overhead of spinning up a compute cluster is arguably overkill. But having that much power available when needed is a compelling reason for moving data science workloads to cloud computing platform.
Run Result
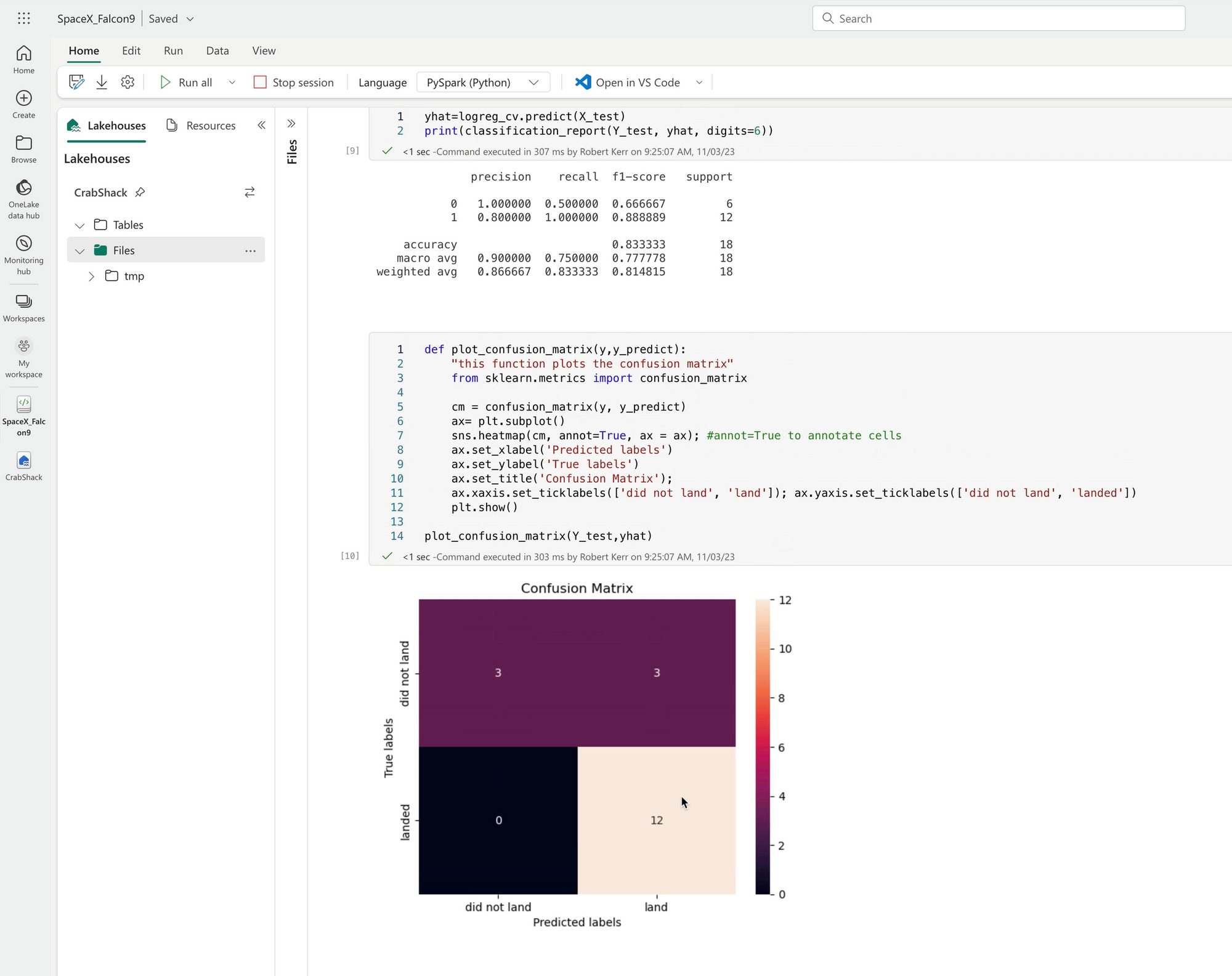
When the job completes, the output is displayed in the notebook just as it was in the local version. Migration of existing solutions couldn't be easier!
Summary
Because Fabric's Synapse Data Science architecture is based on the same open-source Jupyter notebook & Python architecture commonly used on desktop solutions, migrating from desktop to Fabric couldn't be easier.
Of course, this post only scratches the surface of what's possible. As a full end-to-end cloud data solution, Fabric enables many other possibilities for Data Scientists, including:
- Registering models with MLflow.
- Efficiently training & analyzing much larger data sets, enabled by job runs on Apache Spark clusters.
- Directly reading and writing Delta Parquet tables from the Fabric Lakehouse.
- Reading data from Power BI data models (i.e. no need to re-implement PBI calculations in Python!)
- Using batch inference jobs to write predictive data back to the Lakehouse for ingestion into further data pipelines and Power BI models.
- Shared workspaces, data sources and models promote collaboration and break down silos between data scientists, data engineers and data analysts.




