



Large Language Models like the OpenAI GPT models used by ChatGPT are experts at mapping input prompts to the knowledge they were trained on and formulating natural, human-like responses.
Yet their knowledge of our world is limited to their original training data--both in scope and in time. If you've used ChatGPT you may have seen a caveat that that information in a response is based upon data up to a specific date. This is a hint that the model was trained in the past, and it doesn't know about current events.
Similarly, it's very unlikely that your company's data was used in training the original Generative AI model, so an LLM application like ChatGPT probably can't tell you anything about your company's HR policies.
Retrieval Augmented Generation
How can we get a large language model to answer questions about our own data?
There are several techniques to inject custom data into a large language model, and a common approach is Retrieval Augmented Generation (RAG). RAG uses Grounding Data as a preliminary step in answering an LLM prompt. The basic approach is to first search for the knowledge a user prompt relates to, then send the results of that search to the LLM so it can further refine the response based on the grounding data.
When using RAG with text-based document search, there are two basic approaches:
- RAG Keyword Search
- RAG Vector Query
RAG Keyword Search
In this approach, we feed the LLM sections of documents found by matching found in the user prompt against the contents of documents stored in a search engine.
This can be an excellent approach when we want responses to exactly match query input, such as technical questions about products listed on a company website. Keyword RAG isn't as good at understanding homonyms and other ambiguous language structures. For example, if the user asks,
Should the LLM summarize the product specs for an Arris SurfBOARD cable modem? Should it generate a response that lists manufacturers of surfboards in California?
The following is ChatGPT's answer to the question, "What's the maximum speed of a surfboard?":
RAG Vector Search
RAG Vector Search solves language problems such as homonyms by organizing grounding data according to the meaning of language contained in documents rather than the keywords found in them.
This approach is excellent when user prompts are more about concepts than about finding specific information by keyword.
Can I Use Both in the Same Solution?
While a specific deployment may point toward Keyword or Vector searches when providing grounding knowledge to an LLM, it is possible and supported to implement both techniques in the same solution. This hybrid approach isn't covered in this post, but is supported by some backend database soluitions, such as Microsoft Cognitive Search.
Implementing RAG Vector Search
In this implementation example, we'll leverage the following technologies:
- OpenAI's Ada2 LLM to create vectors of for our source data
- Pinecone to store our vectors in a cloud database
- OpenAI's GPT-35-Turbo Generative AI Model to summarize our data into natural language responses.
- LangChain to tie it all together into an interactive chat experience
Let's dive into it!
Importing Dependencies
First let's import all the language dependencies in one place. I've added comments of what role each external library plays in delivering the final solution.
# Base Python data handling environment imports
import pandas as pd
import os
from tqdm.auto import tqdm
import time
# Pinecone is a cloud-based Vector Database we'll use
# to store embeddings
import pinecone
# OpenAI is used for the embedding LLM and GenAI model
# used to generate responses
import openai
# Langchain is middleware that ties together the components
# of the embedding and retrieval pipelines
# The embedding chain creates searchable vectors of our data
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
# A link in the chain to operate a chat session
from langchain.chat_models import ChatOpenAI
# We'll maintain some memory of the chat so follow-up questions
# will be context-sensitive
from langchain.chains.conversation.memory \
import ConversationBufferWindowMemory
from langchain.chains import RetrievalQAFetch API Keys and Set Constants
Both OpenAI and Pinecone are paid services, though both have some level of free usage (which is why I chose them for this walk-through). Each requires an API key to be provided when using the respective services.
I've stored my keys in environment variables and fetch them into constant variables for use later on.
OPENAI_KEY=os.getenv("OPENAI_KEY")
openai.api_key = OPENAI_KEY
EMBEDDING_MODEL="text-embedding-ada-002"
PINECONE_KEY=os.getenv("PINECONE_KEY")
PINECONE_ENV=os.getenv("PINECONE_ENV")
PINECONE_INDEX_NAME="default" # this will be created belowRead Input Data
For this tutorial, I'm using the Stanford Question and Answer (SQuAD) data set to provide grounding data. This data set includes around 18,000 short articles on various topics, such as places (e.g. London) and interesting topics.
I've prepared an extract of this data that includes only the article primary key, subject, and article text.
URL = "https://rhkdemo.blob.core.windows.net/demodata/squad-content.tsv"
df = pd.read_csv(URL, sep='\t')
df.head()Below is the head of the data frame:
Create a Vector Database
For this tutorial, I'm using Pinecone as the data source to store vector embeddings. Pinecone is an easy-to-understand service that is focused on this one job: vector database search.
While not free for production use, there is an experimental free tier level available, which is what I used for this example.
In the code below, line 5 creates a new index in Pinecone, with a dimension of 1536, matching the dimensions the OpenAI embedding model will return when we use it to create vectors.
pinecone.init(api_key = PINECONE_KEY, environment = PINECONE_ENV)
index_list = pinecone.list_indexes()
if len(index_list) == 0:
print("Creating index...")
pinecone.create_index(PINECONE_INDEX_NAME, dimension=1536, metric='dotproduct')
print(pinecone.describe_index(PINECONE_INDEX_NAME))
index = pinecone.Index(PINECONE_INDEX_NAME)The index variable stores a reference to the index in the Pinecone backend that we can use both for loading new vectors and searching the Vector index for content matching user prompts.
Creating Content Embeddings
When a Vector database is created, the next step is to create embeddings for our content and load the embeddings into the vector database.
To calculate embeddings for content, we create an OpenAIEmbeddings object that will be used to submit input text along with our API key.
embed = OpenAIEmbeddings(
model = EMBEDDING_MODEL,
openai_api_key= OPENAI_KEY)Then we extract a list of all the context cells from the SQuAD data sample (see data frame above) and submit them to OpenAI in small batches.
The return from OpenAI will be the corresponding embedding for each content item. We'll store these embeddings along with the original text and document ID in the Vector database.
# Submit document text to OpenAI to calculate embeddings of each document
docs = batch['context'].tolist()
emb_vectors = embed.embed_documents(docs)
# Add embeddings, associated metadata, and the keys to the vector DB
to_upsert = zip(ids, emb_vectors, meta_data) index.upsert(vectors=to_upsert)An embedding is nothing more than a multidimensional map of where each submitted piece of content is located relevant to all other pieces of content. Content with vectors close to each other have similar semantic meaning.
For example, the following content with a subject of "London", is a paragraph of text beginning with "Within the City of Westminster...". It's calculated embedding vector* is an array of 1,536 floating point numbers beginning with 0.168996044.
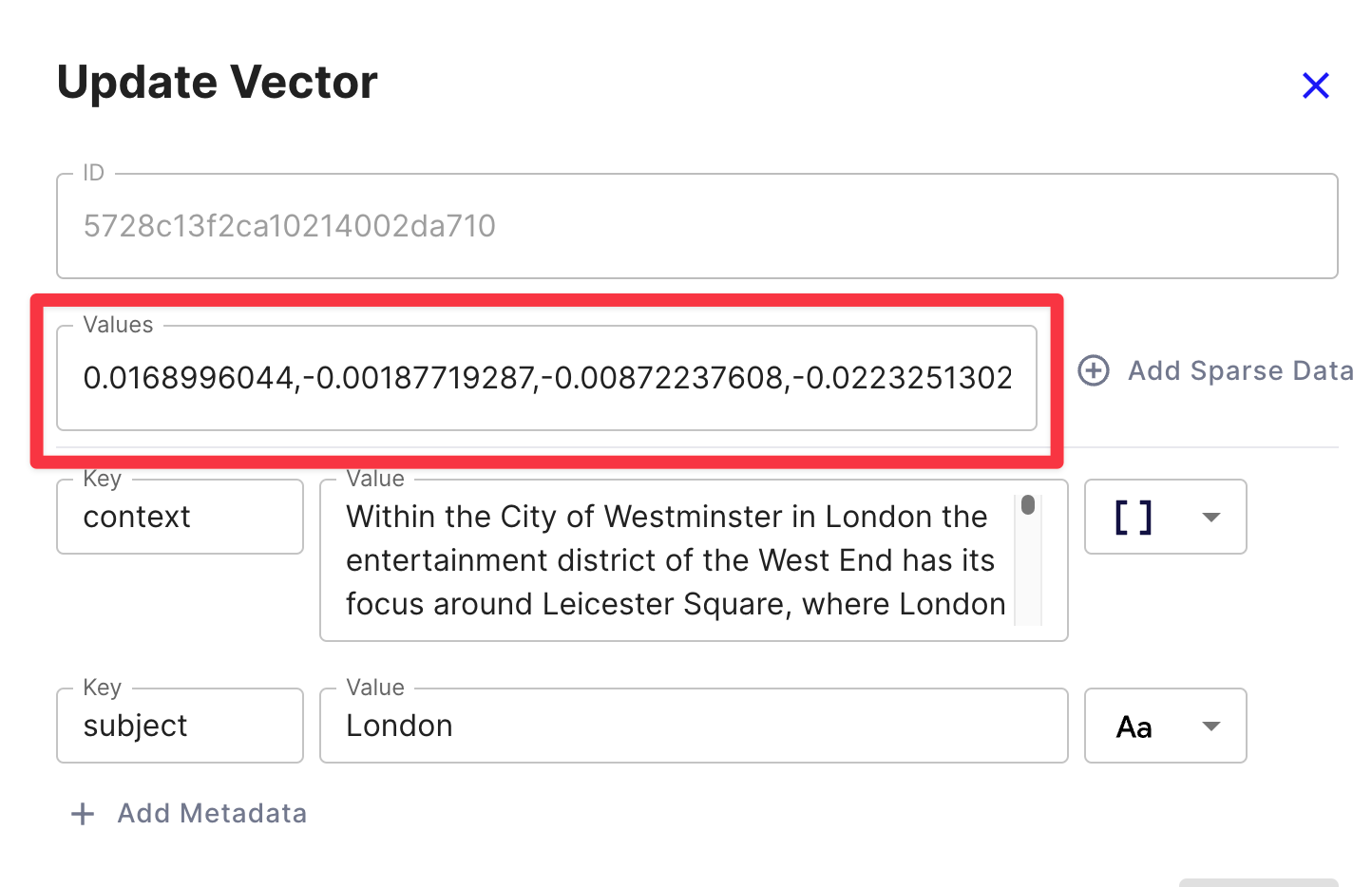
All content in the Vector database has a unique list of 1,536 dimension values. To determine the proximity between two pieces of content involves a mathematical calculation that ultimately determines the distance--in language meaning--between the two pieces of content.
While it is possible to calculate embeddings yourself, it's not necessary. The Vector database calculates embedding distances for us!
With the content embeddings calculated and loaded into the Vector database, we can move on to using the embeddings to provide grounding data to our chatbot.
Creating the Chatbot
To create the Chatbot, we use LangChain to tie together a pipeline consisting of three operations:
- Creating an embedding of a user-provided prompt. The embedding is created identically to the stored content embeddings.
- Query the Vector database (Pinecone in this case), for grounding content that's semantically similar to the user prompt.
- Combine the user prompt with the grounding content and previous conversation turns.
- Submit the original prompt, the grounding data, and the memory of previous turns to the LLM, and wait for the response.
- Provide the LLM's response back to the calling application for display to the user.
Testing the Chatbot
To test the chatbot, we submit a few prompts, and view the response:
User Prompt: qa.run("What do people like about London?")
Response: People like London for a variety of reasons. Some of the things that people appreciate about London include its rich history and cultural heritage..
User Prompt: Is it expensive to live there?
LLM Response: Yes, it is expensive to live in London. It has the highest property prices of any European city...
User Prompt: Does dell make surfboards?
LLM Response: No, there is no information in the provided context that suggests Dell makes surfboards.
User Prompt: Do they make laptops?
LLM Response: Yes, Dell manufactures laptops.
Summary
While Generative AI models are some of the smartest tools to be created by computer science yet, they still need customization and guidance to solve concrete use cases. The most importance of these is how to help an LLM to return accurate, relevant responses.
There are many ways to provide accuracy guidance to a Generative AI system, and among these is Retrieval Augmented Generation, or RAG. The specific RAG approach covered in this post is Vector Embedding of text content, as well as the use of LangChain to build a chatbot with conversational memory.




