Models developed in Fabric can also be deployed in other environments like Azure Machine Learning (Azure ML), other cloud providers, or even on-premises deployment. In this post we'll take a look at how to export models trained in Fabric and deploy them into other compute infrastructures.
The Use Cases for Exporting Fabric Models
Fabric's Data Science workload uses the distributed Spark cluster which provides the ability to train ML models using large data sets, and trained models can be used with Synapse Transformers to efficiently score large input data efficiently at scale.
However, there may be other production ML uses for the models we trained in Fabric. Some examples:
- Deploying of real-time inference endpoints to REST web servers for consumption by other applications.
- Deploying batch endpoints to serve ETL pipeline use cases.
- Re-using models trained in Fabric in applications running in other cloud infrastructures (AWS, Google, IBM, etc.) or in custom compute instances on-premises or on edge devices.
Because we can export Fabric models, we can leverage Fabric's scalable compute and access to OneLake data sources for training, and repurpose trained models in many other applications across the enterprise.
Walk Through
Export the ML Model from Fabric
The first step in deploying a Fabric ML model is to export it. In this basic walk-through, I simply export the model to my local Windows system.
Exporting a model from Fabric is easy--just tap the Download ML model version button in the UI.
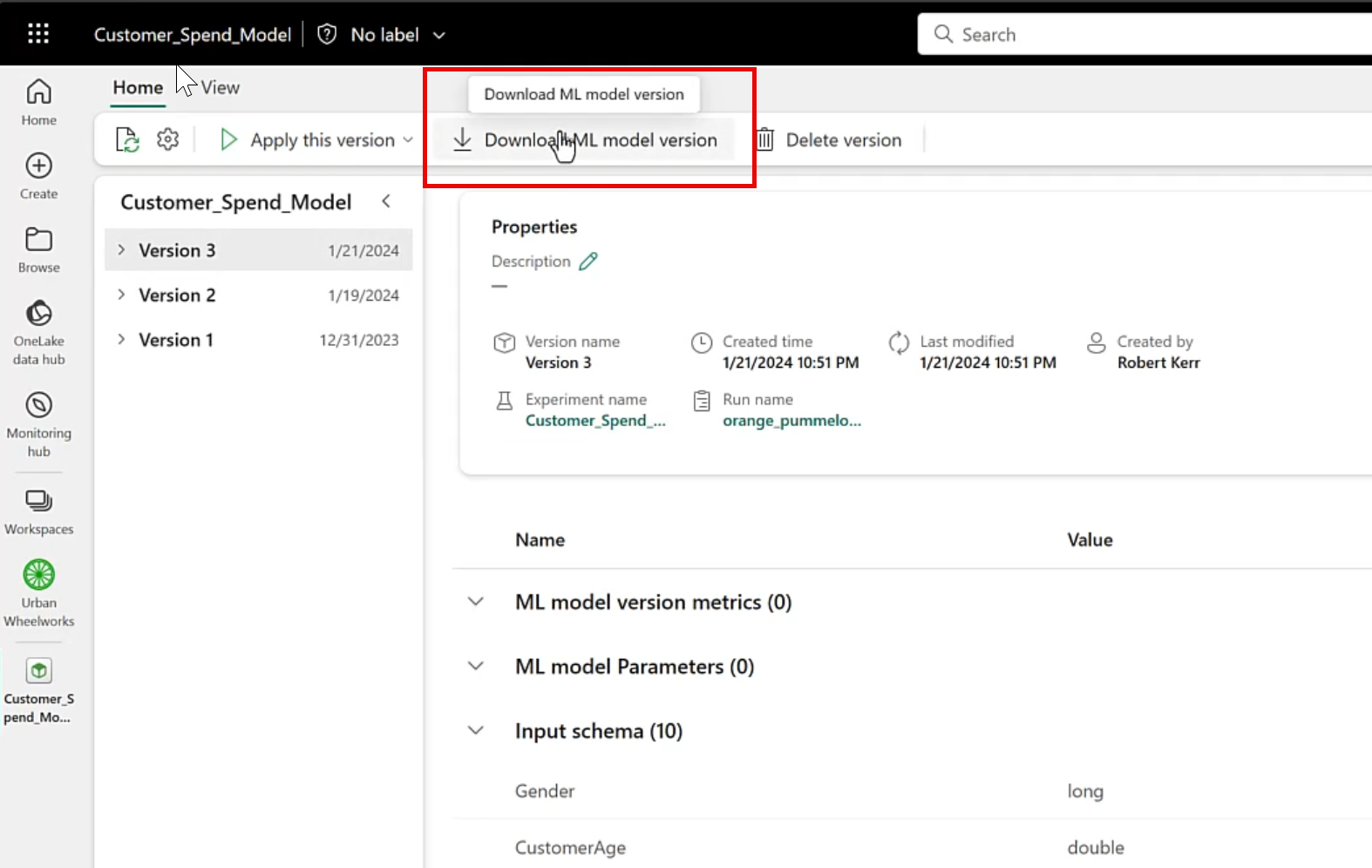
Explore the contents of the downloaded file
Fabric will combine the ML Model along with a Python Object Serialization file (a/k/a pickle file) having a .pkl extension, and YAML files (.yml) that describe to other platforms the structure and interface provided by the model. All these files are packaged into a .zip file, which will be placed in your Downloads folder.
If you open the .zip file, you can review the model and metadata files before deploying them to other systems.
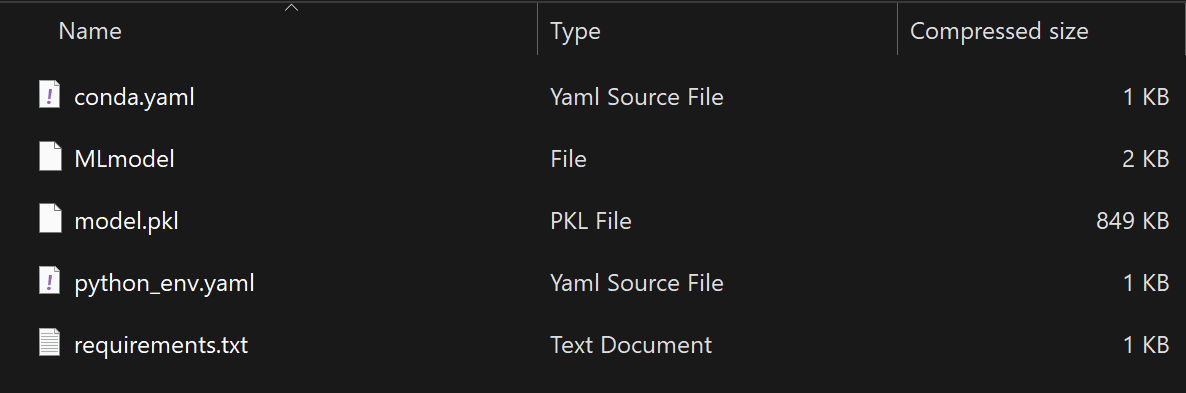
The contents of the .zip file contain YAML files that define the runtime environment a serving compute engine needs to provide for the model, and the input/output interface (data structures) needed to call the model.
Upload the Model to Azure ML
In this example, we're going to deploy an Azure ML real-time inference endpoint to publish the model to the Internet via a RESTful web service.
While it is possible to deploy an endpoint using a model from our local file system, I'm going to register the model in and Azure ML workspace, and use the Azure ML Studio web UI to deploy the endpoint.
To upload the model, we'll use the Register/From local files menu in Azure AI Machine Learning Studio, and then press the Register button at the bottom of the screen.
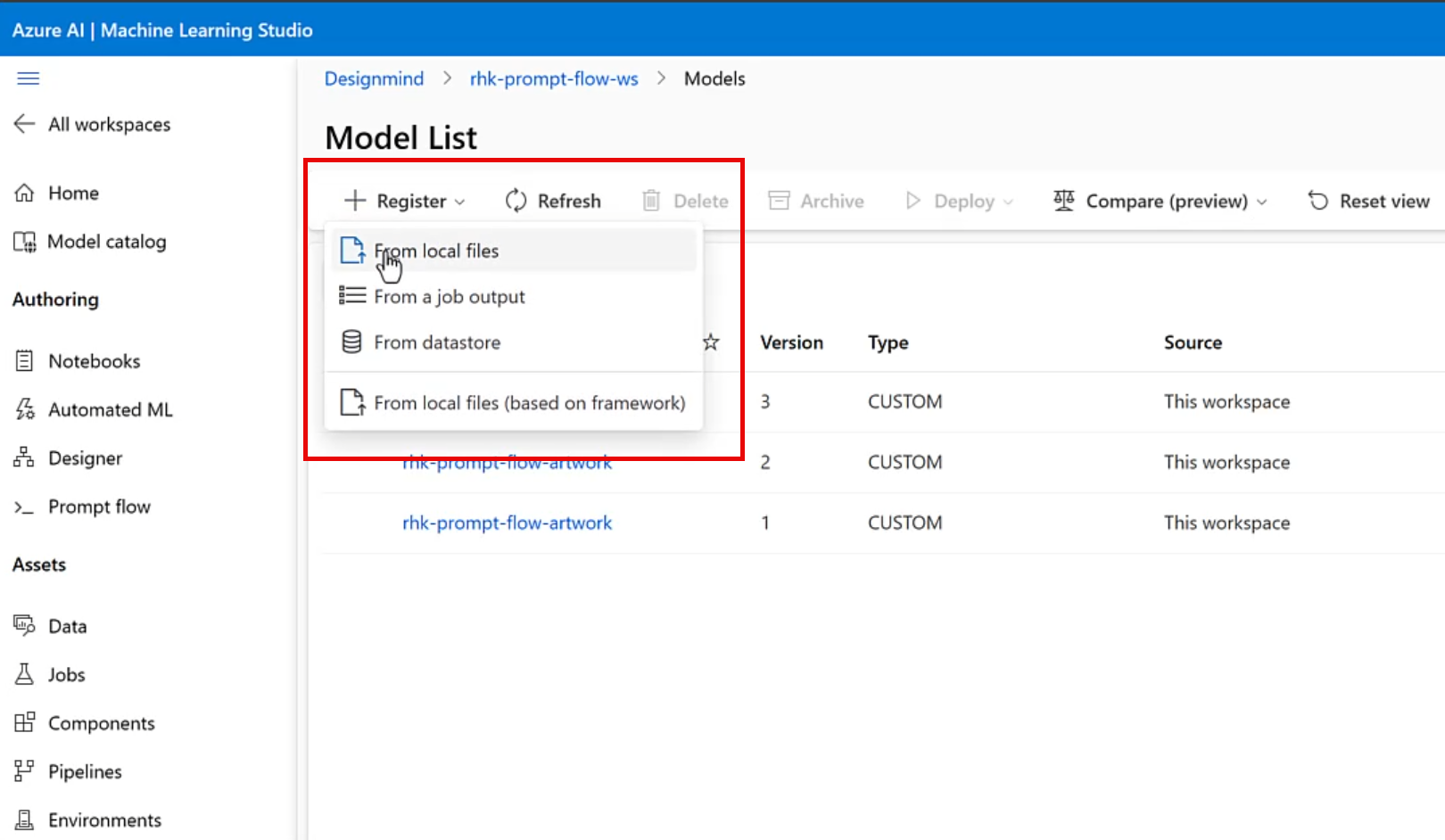
After uploading the files, the new model is available in the Models page of the Azure ML Workspace.
Deploy the Model to an Endpoint
Once the model is registered in the Azure ML workspace, click on the model name, and then select Real-time endpoint from the Deploy menu.
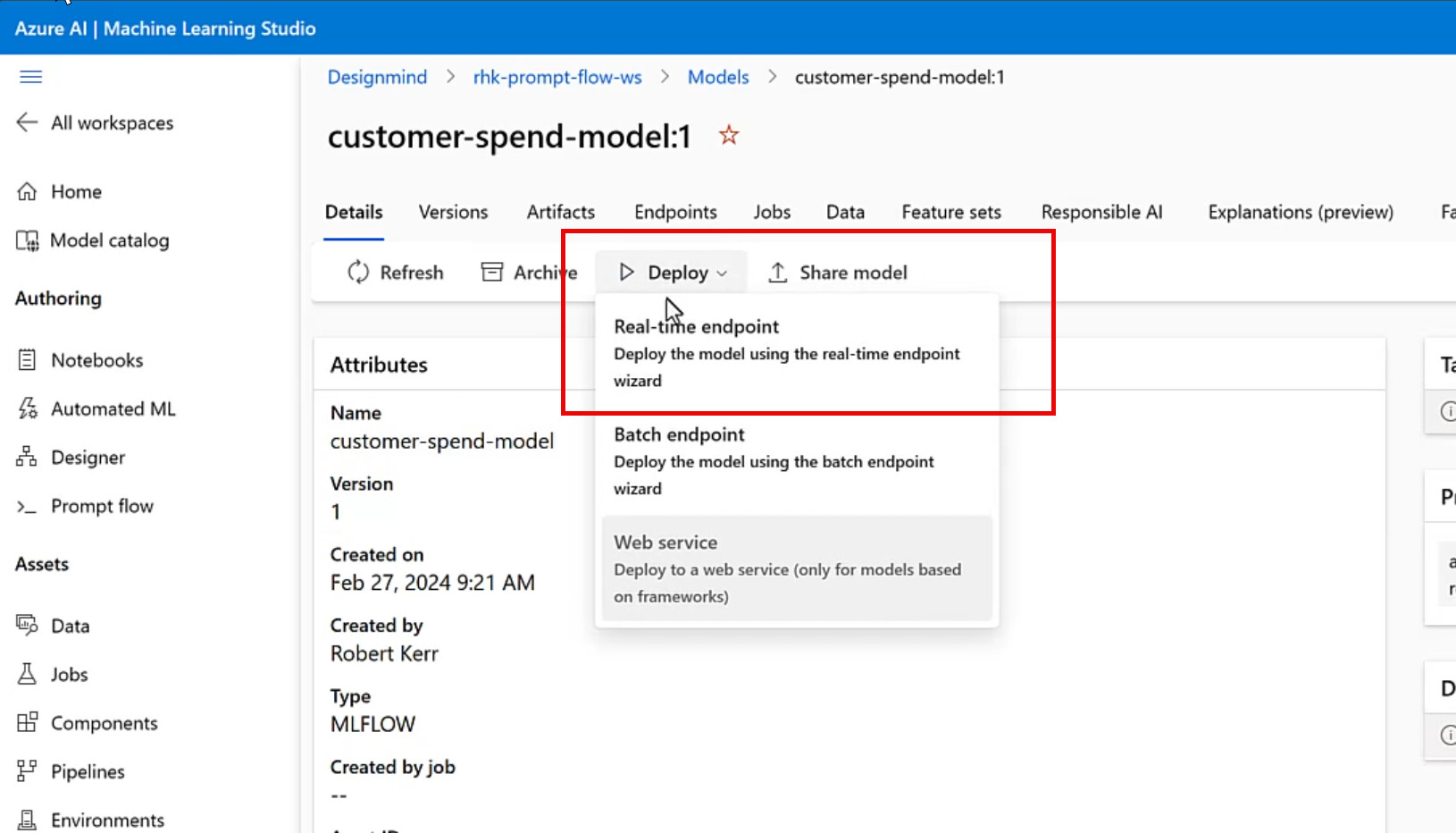
Configure the Endpoint and Deployment
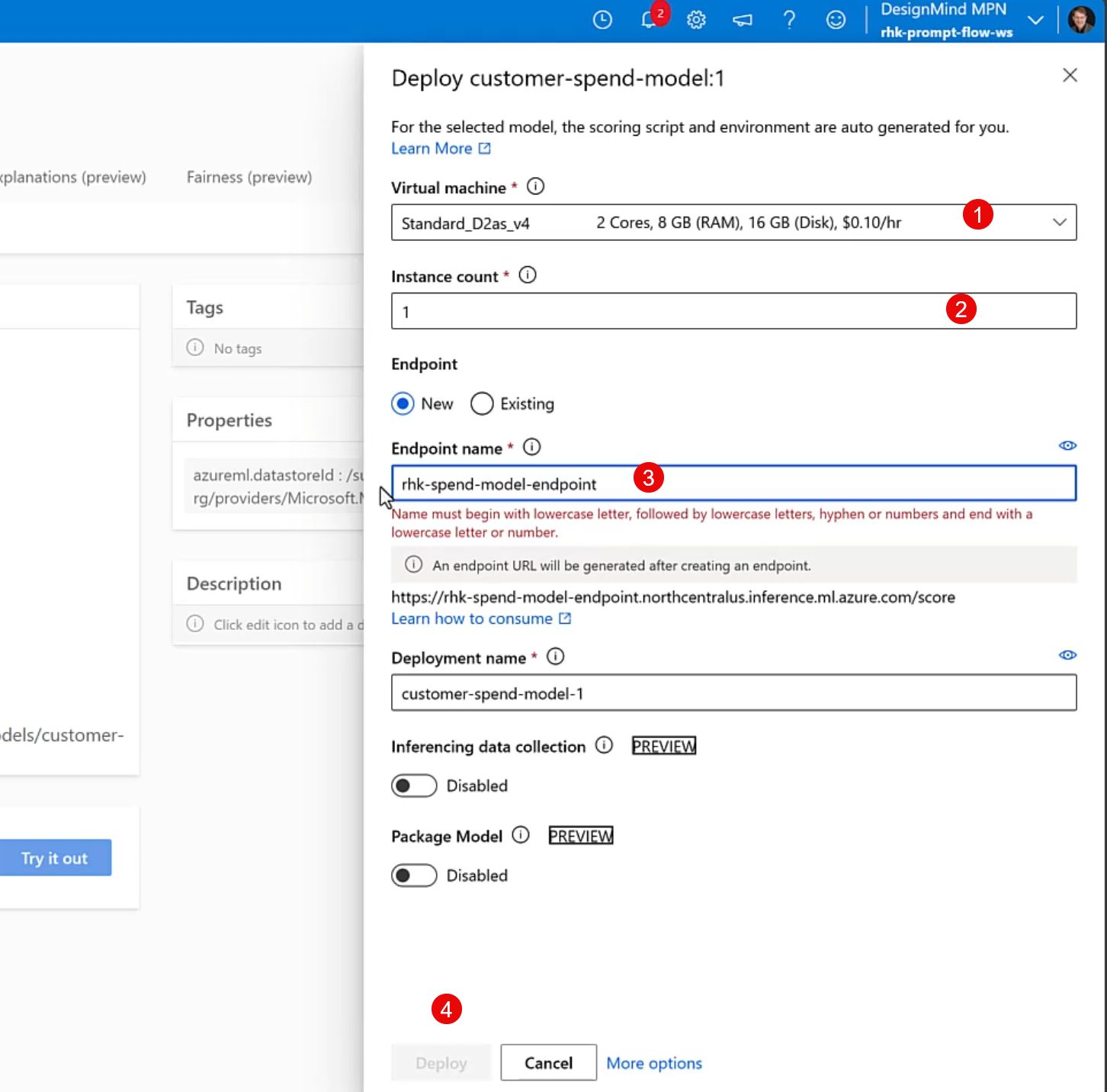
A model opens up to configure the compute to use for the endpoint, and to specify the deployment name.
Specify the compute size desired for the endpoint, and the names for the endpoint and deployment, then tap the Deploy button.
Test the Deployment
After the deployment completes (10-15 minutes, typically), we can make a quick "smoke test" within Azure ML Studio to ensure the deployment is functional, and we're using the correct data structures when calling it.
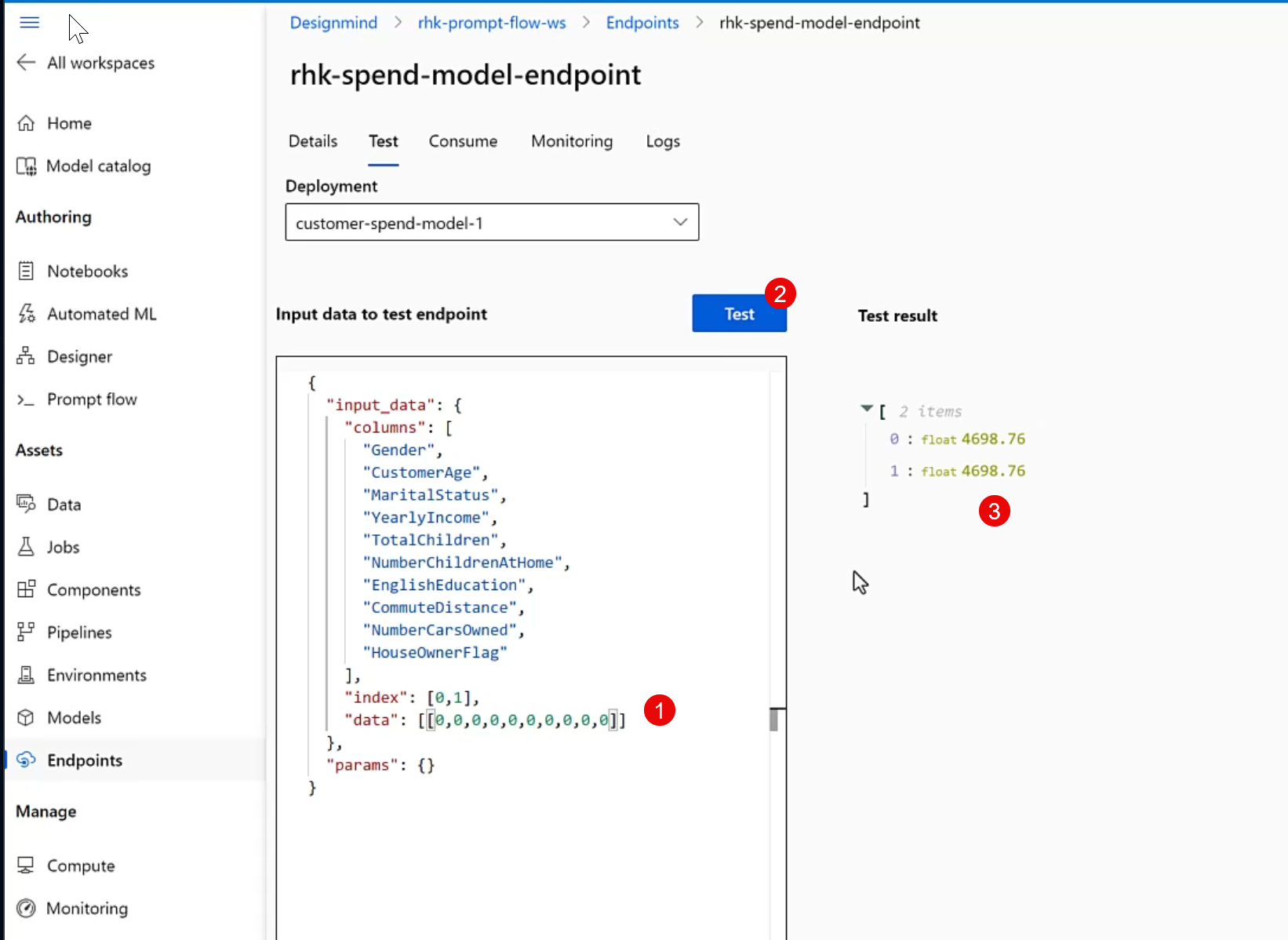
Once the interactive test succeeds, it's time to move on to consume the model from outside the Azure ML environment.
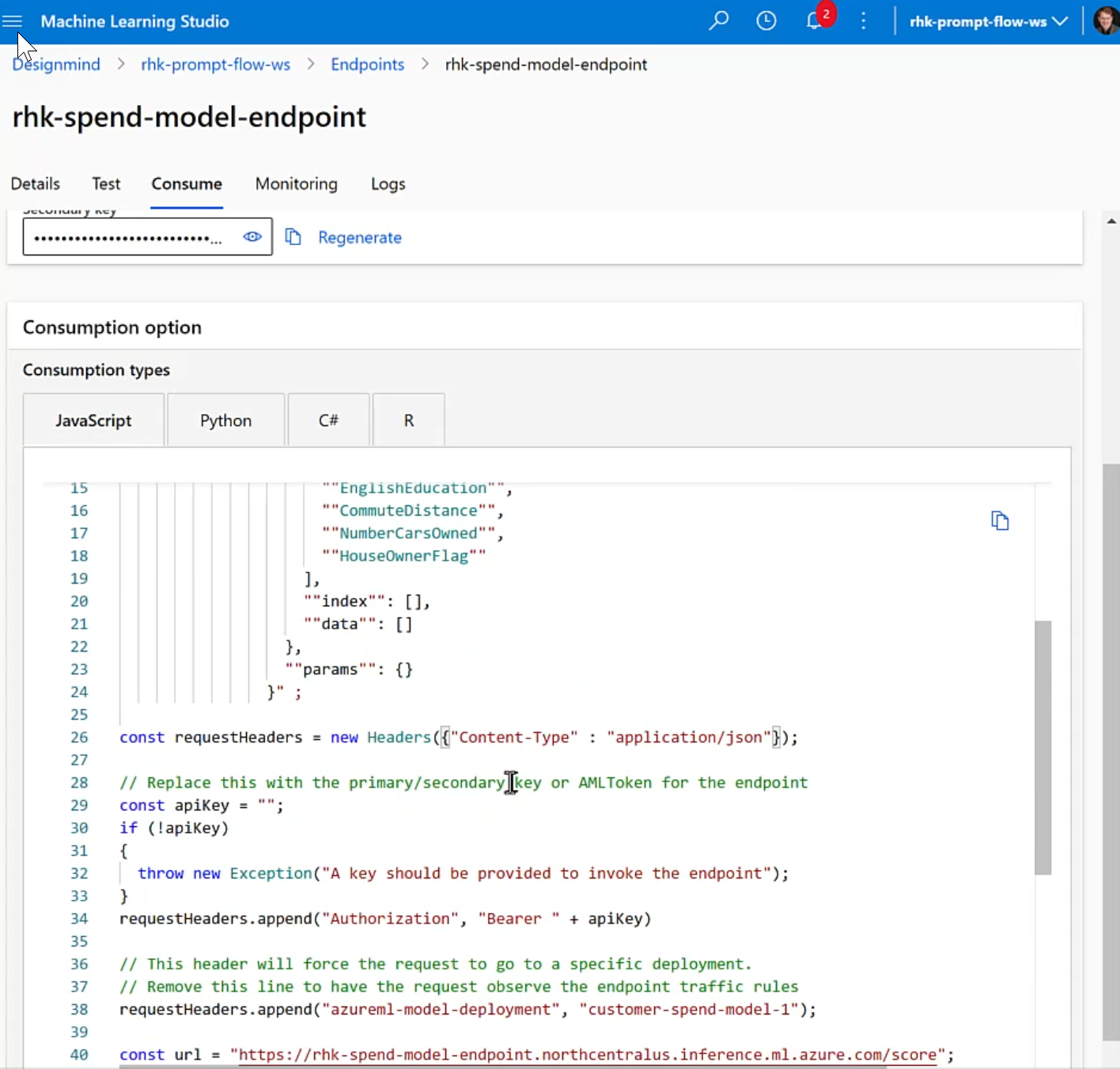
Consuming the Deployment via the REST Endpoint
We can now send data for scoring to the model deployment via the endpoint using any application or programming language that supports RESTful POST requests. Azure ML provides boilerplate code in JavaScript, Python, C# and R.
For this post, I'll use Postman to test the endpoint from the public Internet (using the code samples provided by Azure ML as inputs to the Postman call configuration).
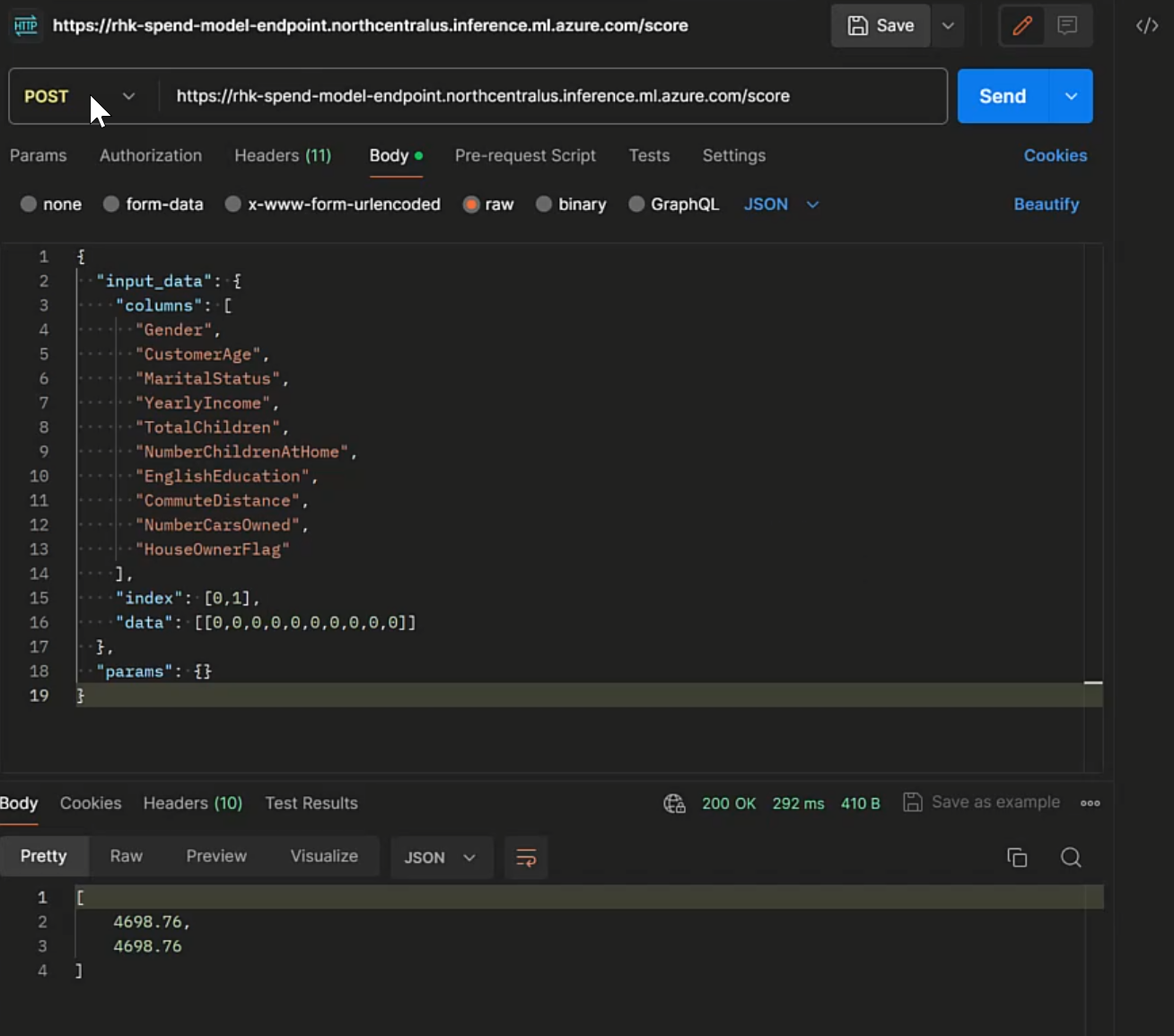
Calling the Endpoint from Postman
Making the API call to the public Internet endpoint verifies the endpoint and deployment are configured correctly, and the input/output interfaces are working as expected.
Summary
Microsoft Fabric has a rich Data Science workload, backed by Synapse ML and scalable Spark compute, which gives us excellent tools for training ML models and using them to transform data in our data lakes.
Our models are created in standard formats, and registered within Fabric workspaces using MLflow, making it easy to repurpose them in other data science environments!
In this post, I deployed a Fabric model to Azure Machine Learning, and repurposed a model trained in Fabric for use by applications via scalable Azure compute clusters. The ability to export and repurpose models opens endless opportunities!