



Microsoft Fabric includes a feature called Semantic Link, which can be used to access Power BI data from Python Jupyter Notebook. This feature essentially provides a two-way data source relationship, where Machine Learning models can be used to enrich Power BI models--while at the same time data modeled in Power BI can become a data source for data scientists creating machine learning models.
Why Use Power BI as a Data Source?
There are some interesting use cases for Semantic Link, and this article discusses using the feature to leverage Power BI business intelligence data as a source for models. Ther are some compelling reasons to use this pattern:
- Power BI data models often have complex, advanced calculations already implemented. Accessing Power BI measures and calculations can avoid the need to re-implement the same calculations at the Data Science level.
- Power BI is excellent at serving slice & dice, cross-drill data results with high performance even when run over high data volumes.
- Building machine learning models over the same data sources used in business intelligence use cases helps ensure consistency by using pre-validated, accepted data sets as a source for data science analysis.
Building a Semantic Link Solution
The following walk-through illustrates how to build the following solution:
- Enumerate the data models available in a Fabric workspace from Python.
- Connect a Jupyter Notebook to a Power BI data model.
- Inspect the calculated measures available in a Power BI data model, and their underlying DAX calculations.
- Query data from the Power BI data model and extracting it into a Pandas
DataFrame. - Building a scikit-learn regression model using the results of the Power BI query.
- Registering the resulting model with the Fabric model registry using MLflow.
The walk-through part of this post is available as a YouTube Video! The written post continues after the embedded video.
The Power BI Dashboard
The source of data for this walk-through is a Power BI PBIX dashboard hosted in a Fabric workspace.
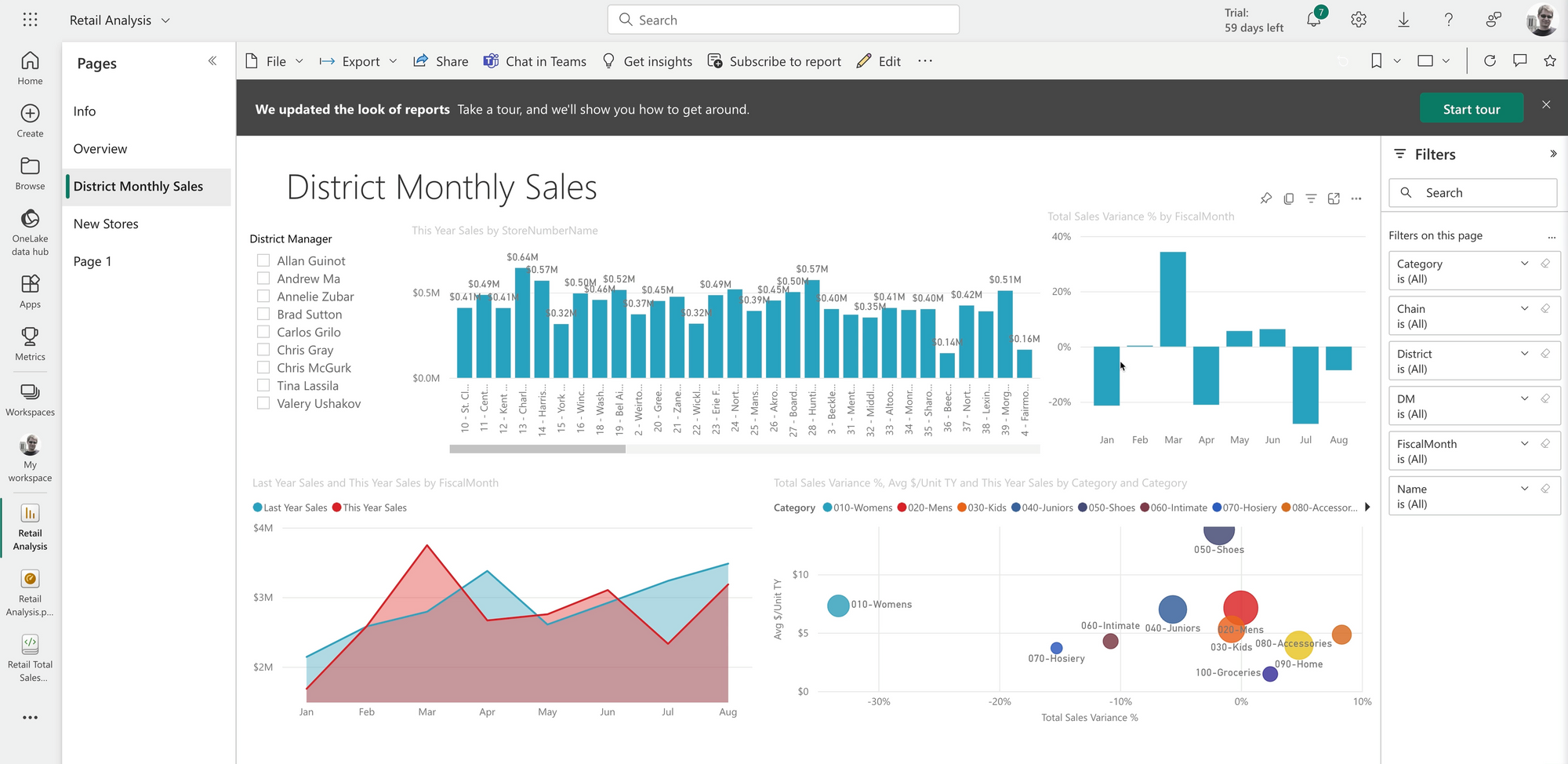
When we fetch data from Fabric, the Semantic Link feature will query the Power BI data model for us, returning data as a Pandas DataFrame.
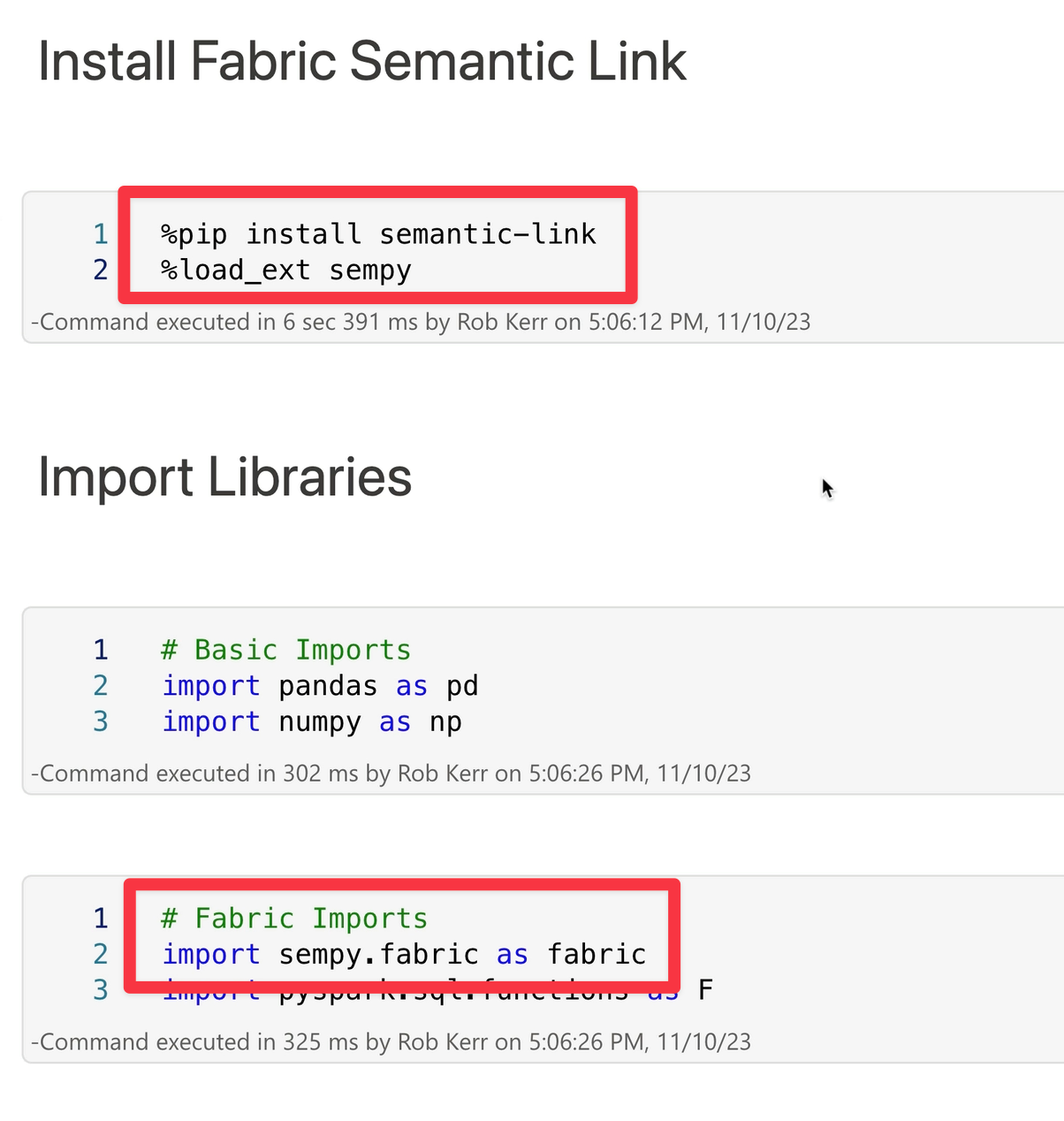
Importing Dependencies
To access data via Semantic Link, we import the sempy.fabric Python library:
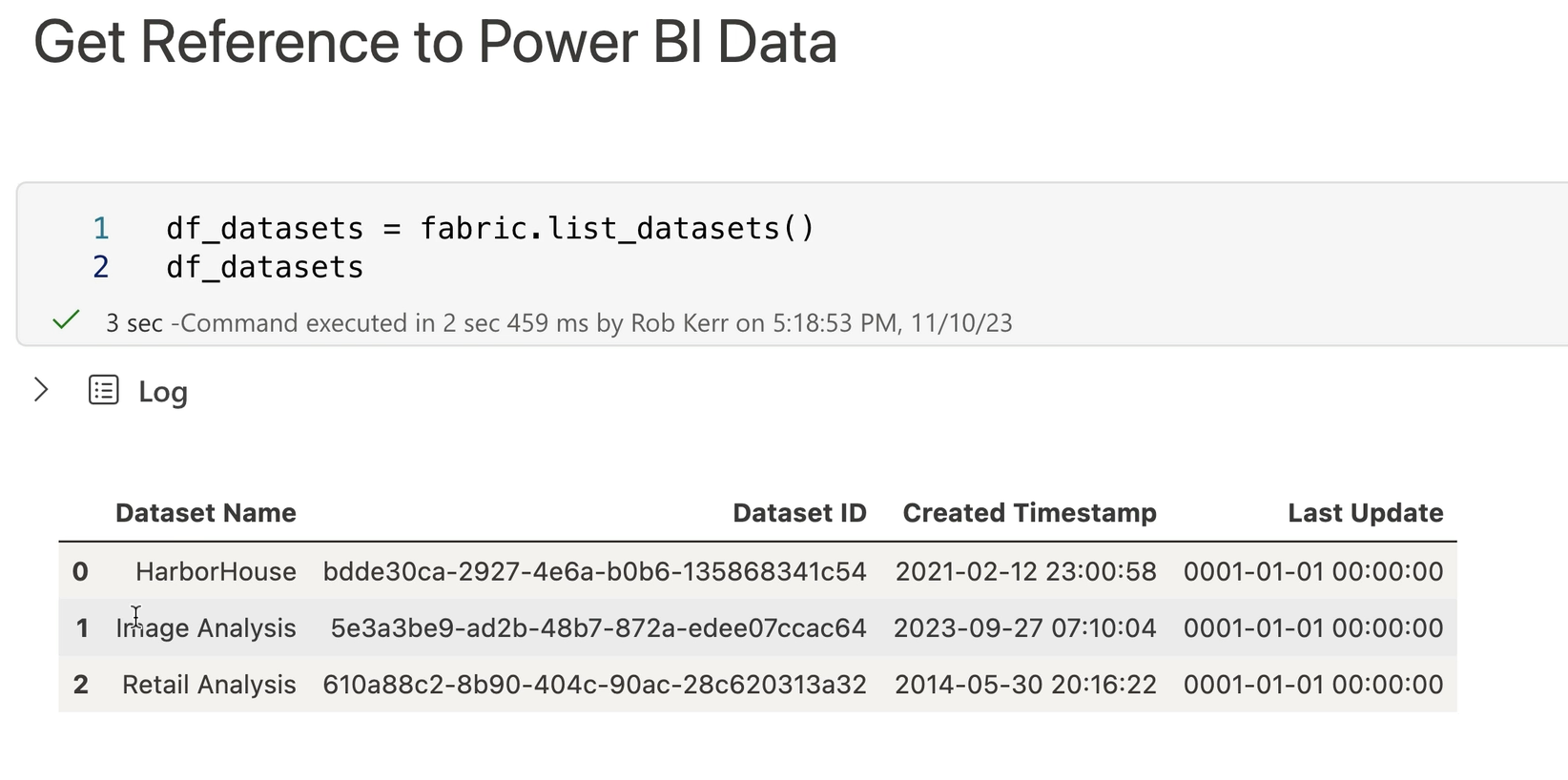
Enumerating Models in Fabric
Next, we enumerate the models available in Fabric. Among other models, this list will show the data sets hosted by Power BI PBIX files. In this example, we'll use the Retail Analysis data set from the PBIX file of the same name.
Inspecting the Power BI Data Model
While our main interest in this example is extracting data from the Power BI data source, we can also use the fabric object to inspect the data model, list measures, and even make changes to the data model.
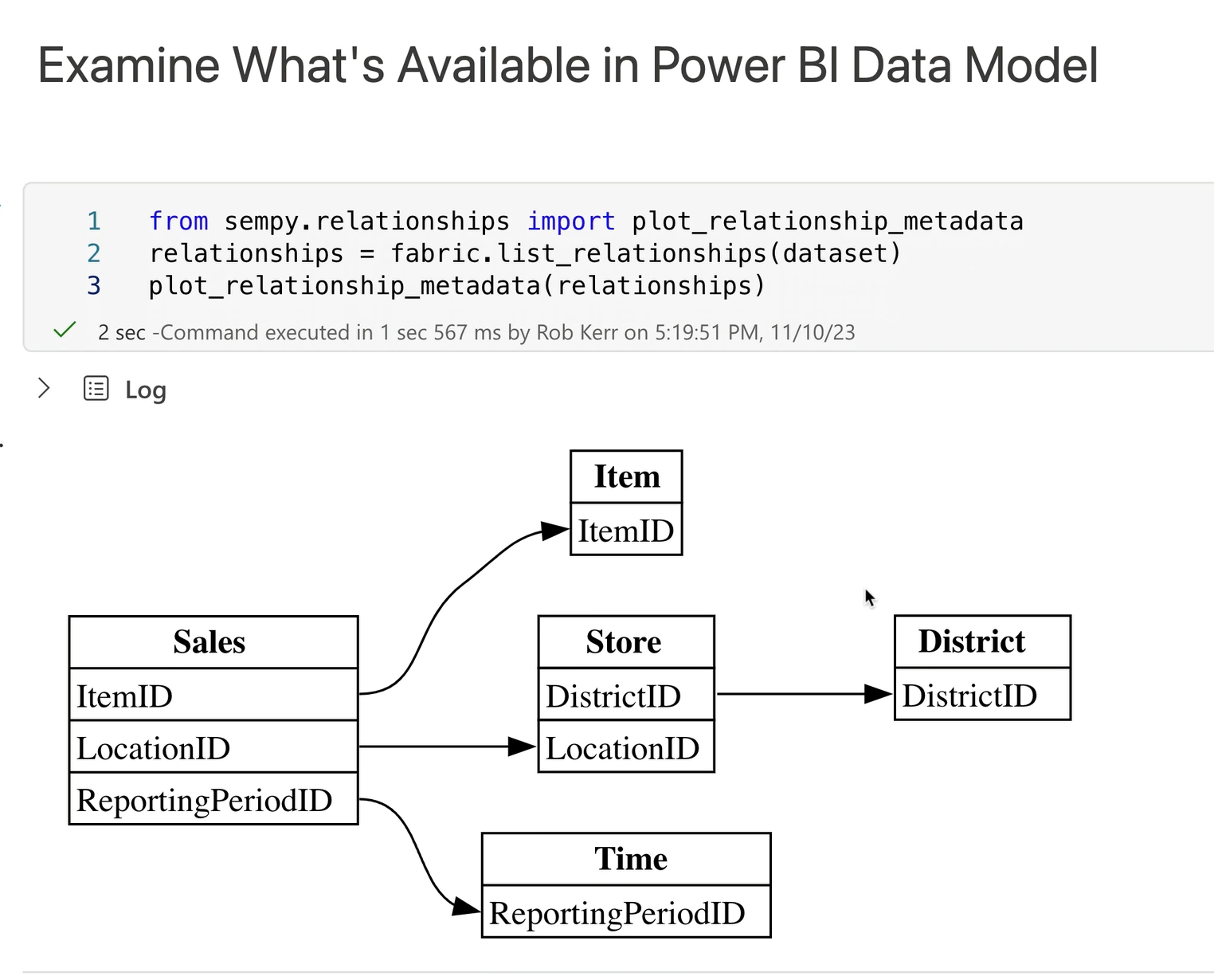
The Semantic Link SDK can even enumerate measures with formulas from the Power BI data model:
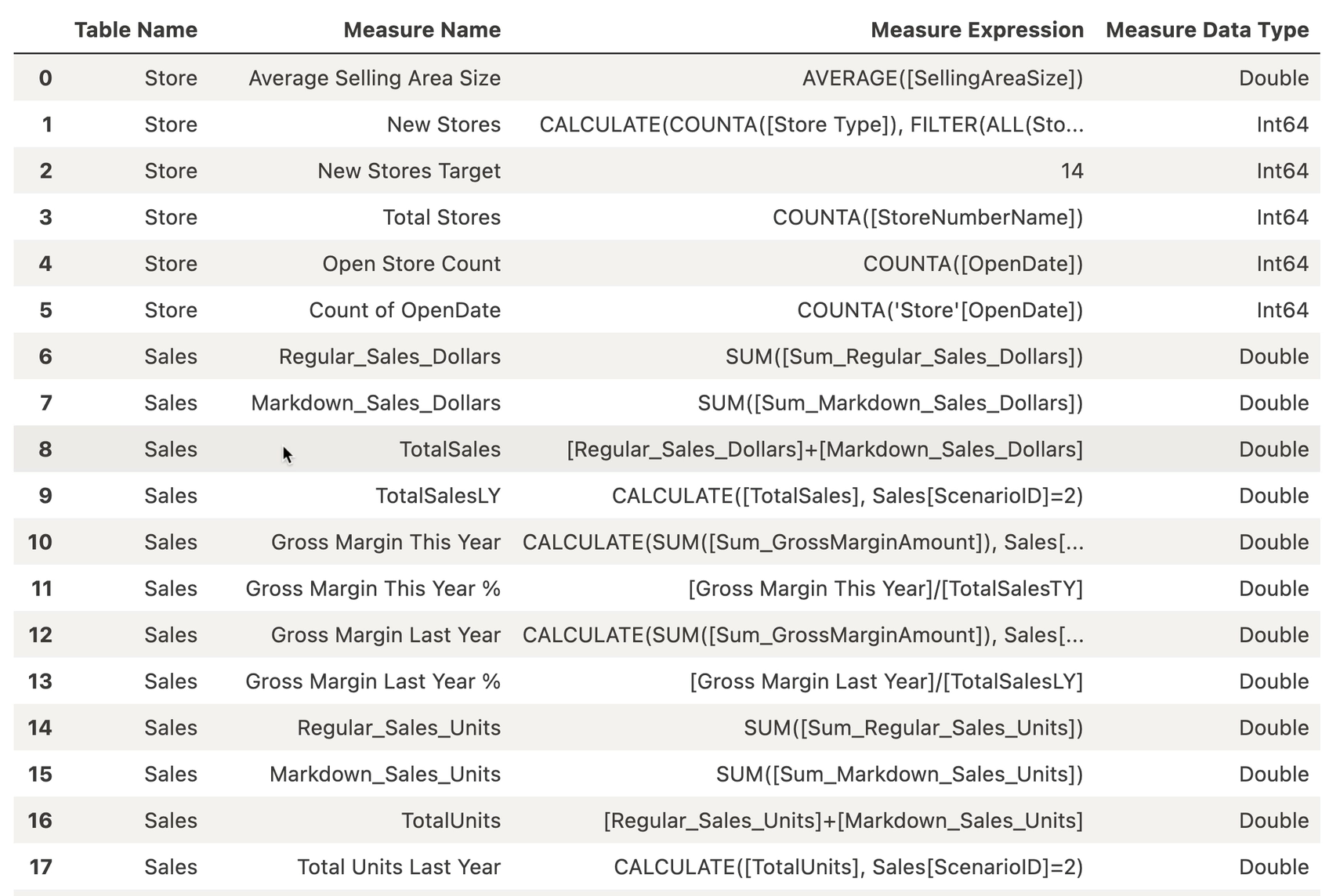
Query the Power BI Data Model
Next, we can query the Power BI data model to extract data to use in building a Machine Learning model.
In this case, we'll select TotalSales as the metric to predict with a regression model, a set of categorical metadata about stores, and another metric Average Unit Price to use as the independent variables in the regression analysis.
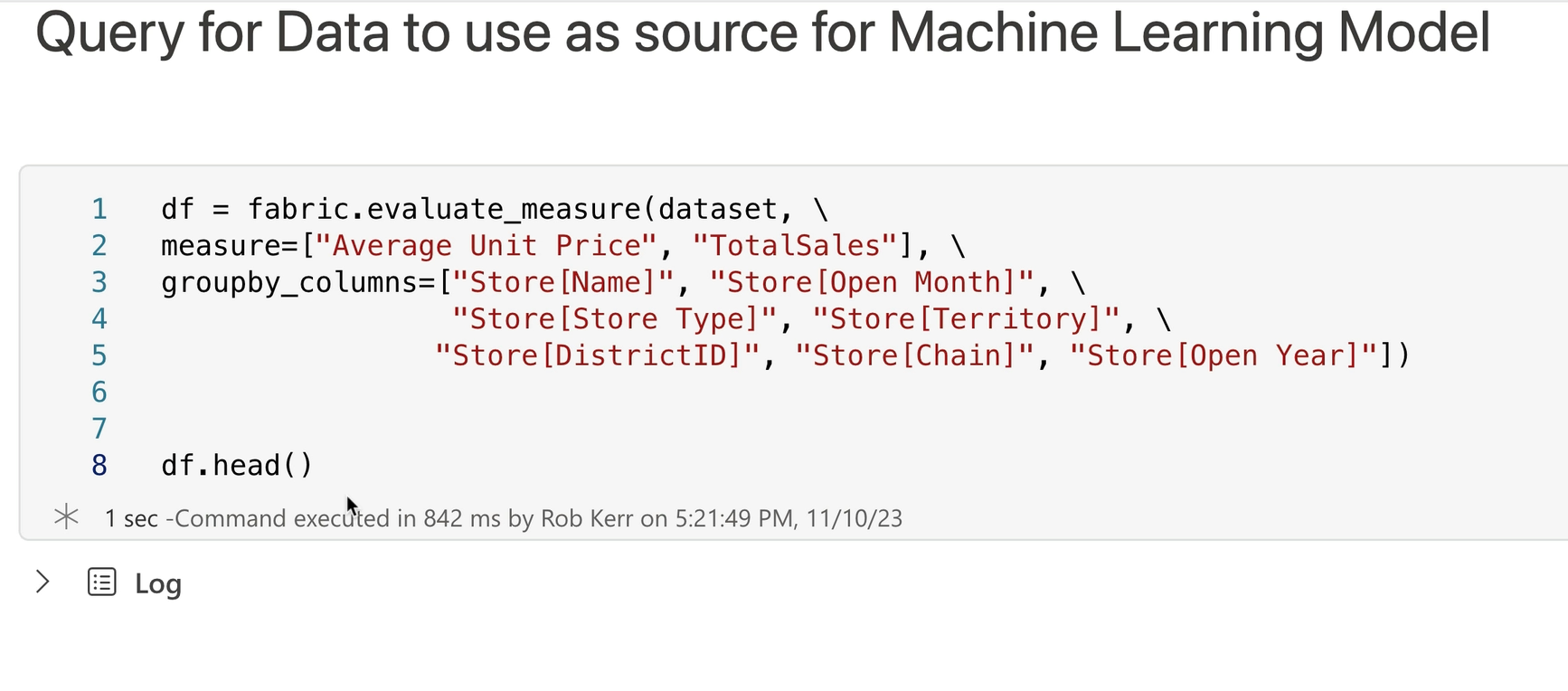
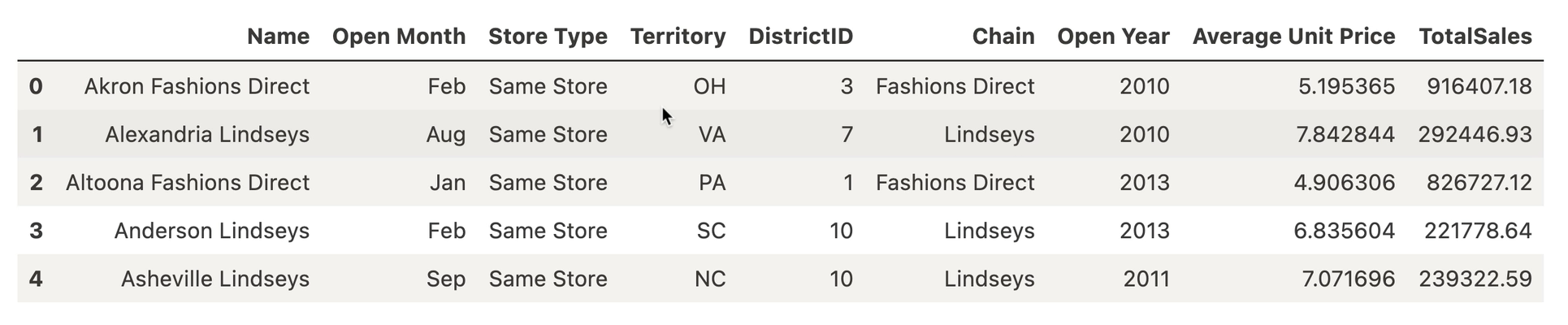
Results of the query are returned as a Pandas DataFrame:
Training the Regression Model
After some data wrangling to prepare data for machine learning model training, we use Scikit-learn to train a regression model.
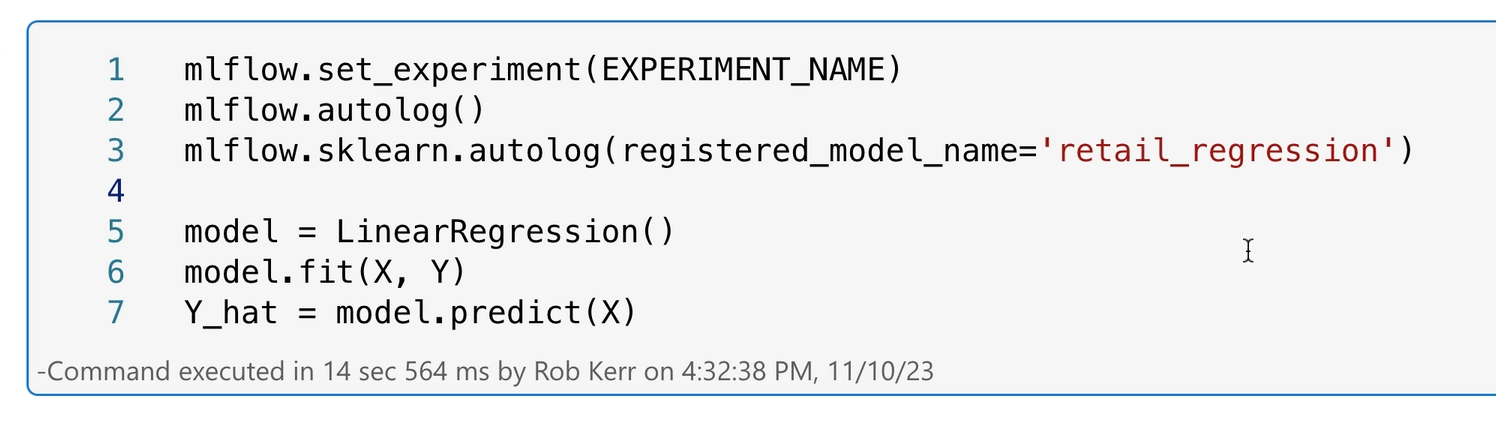
In this case we do the following:
- Switch on MLflow autolog, which will automatically log metrics to Fabric data science for documentation and later review (line 3)
- Train the linear regression model (line 6)
- Generate a prediction for the original data set using the model (line 7)
Evaluating the Model
We can use typical processes in Python to evaluate the model, and if needed iteratively improve it before publishing the final version.
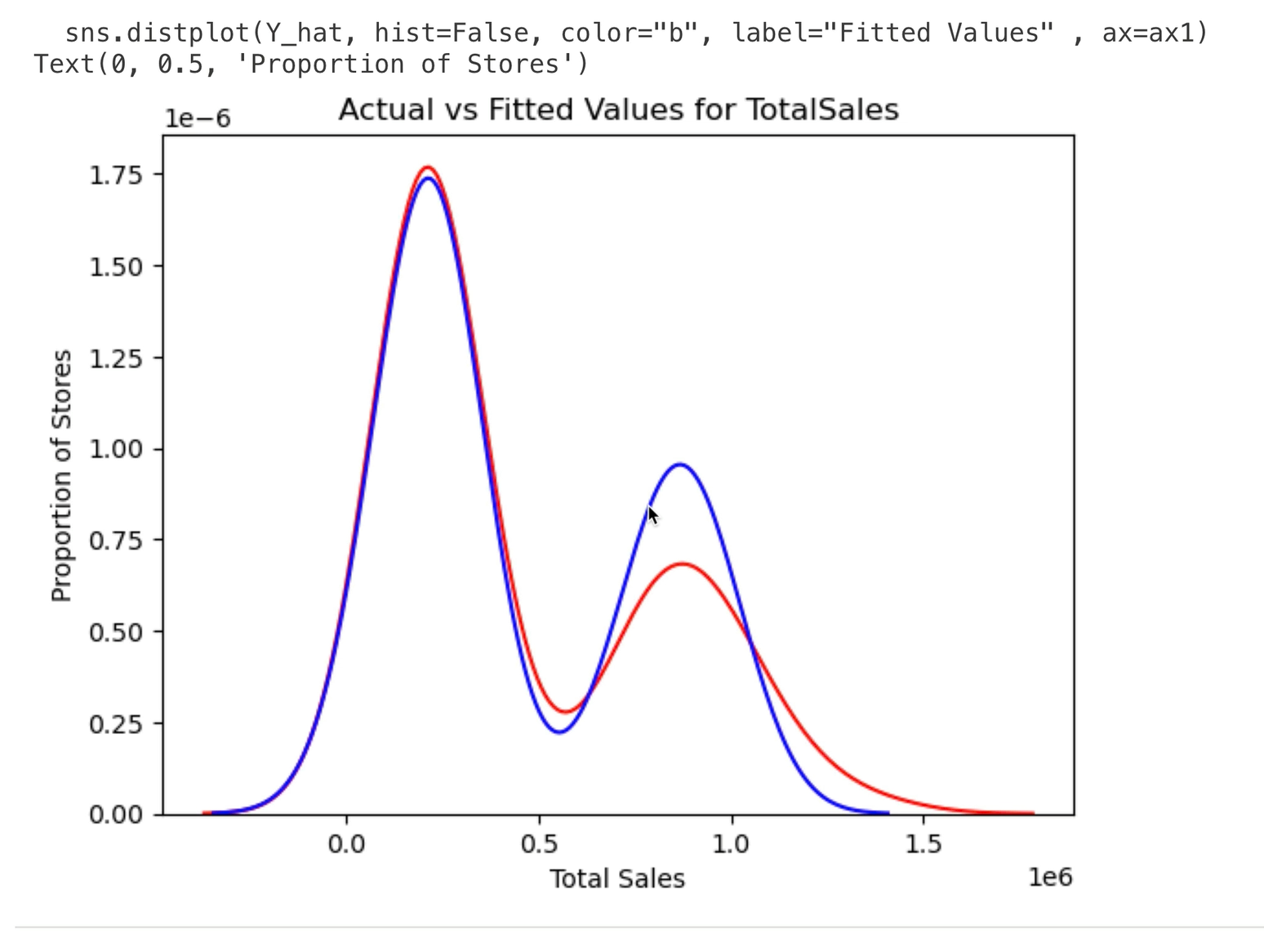
Reviewing the Model in Fabric Data Science
By switching on autolog in MLflow during training, the training run we conducted was added to Fabric Data Science as a run within an experiment.
We can then return to Fabric and review the experiment, the run we did, and the performance of the resulting model.
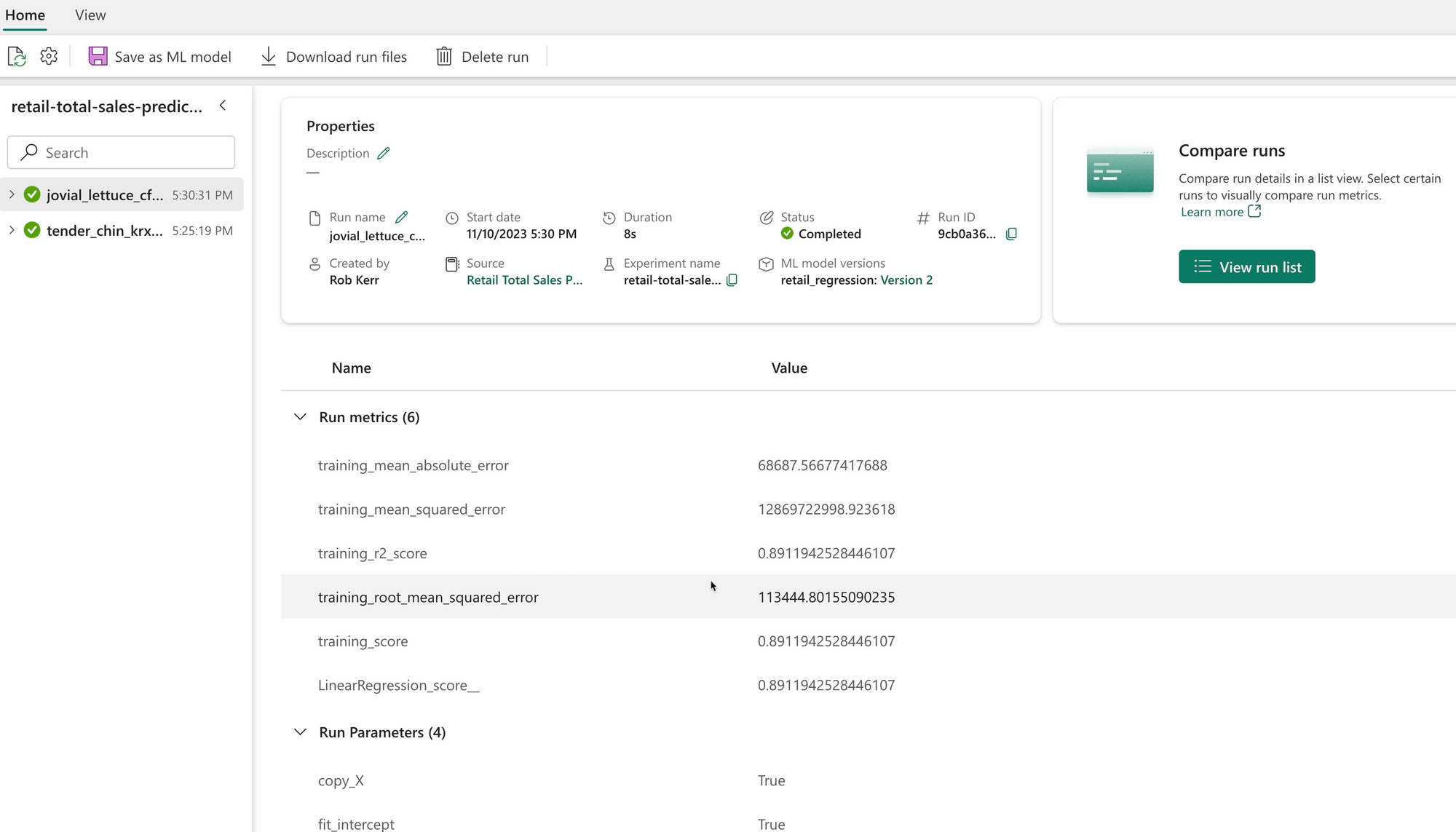
If we're happy with the model, we can publish it, or even download it and deploy it outside Fabric.
Summary
Fabric Semantic Link is a feature that completes the full circle of data sourcing for data managed in Fabric. Not only can data scientists create data for use in BI solutions, but they can also use the output of BI/Data Analysist as source data for their own work.
Because Semantic link is available as a standard Python library with Pandas DataFrame support, it integrates seamlessly with the workflow most data scientists are already familiar with.




