



Microsoft Fabric's underlying architecture is known as OneLake -- a unified data storage foundation that consolidates an organization's data estate in a single, unified data lake. OneLake can incorporate data that's physically not stored in OneLake through the use of OneLake Shortcuts.
Data stored in other public clouds such as AWS S3 buckets aren't physically stored in Azure OneLake, but they can be logically accessed from a Data Lake by creating a shortcut within a Fabric Data Lake, wher the data is read from the external source on demand.
In this post we'll do the following:
- Create an AWS S3 Bucket
- Add data to the S3 bucket
- Create a shortcut to access the S3 data from a Fabric Lakehouse
Our End Goal
When we're finished with the configuration, we'll be able to access data from the AWS S3 bucket as if it was a part of the Fabric Lakehouse. Here's an image of our end goal:
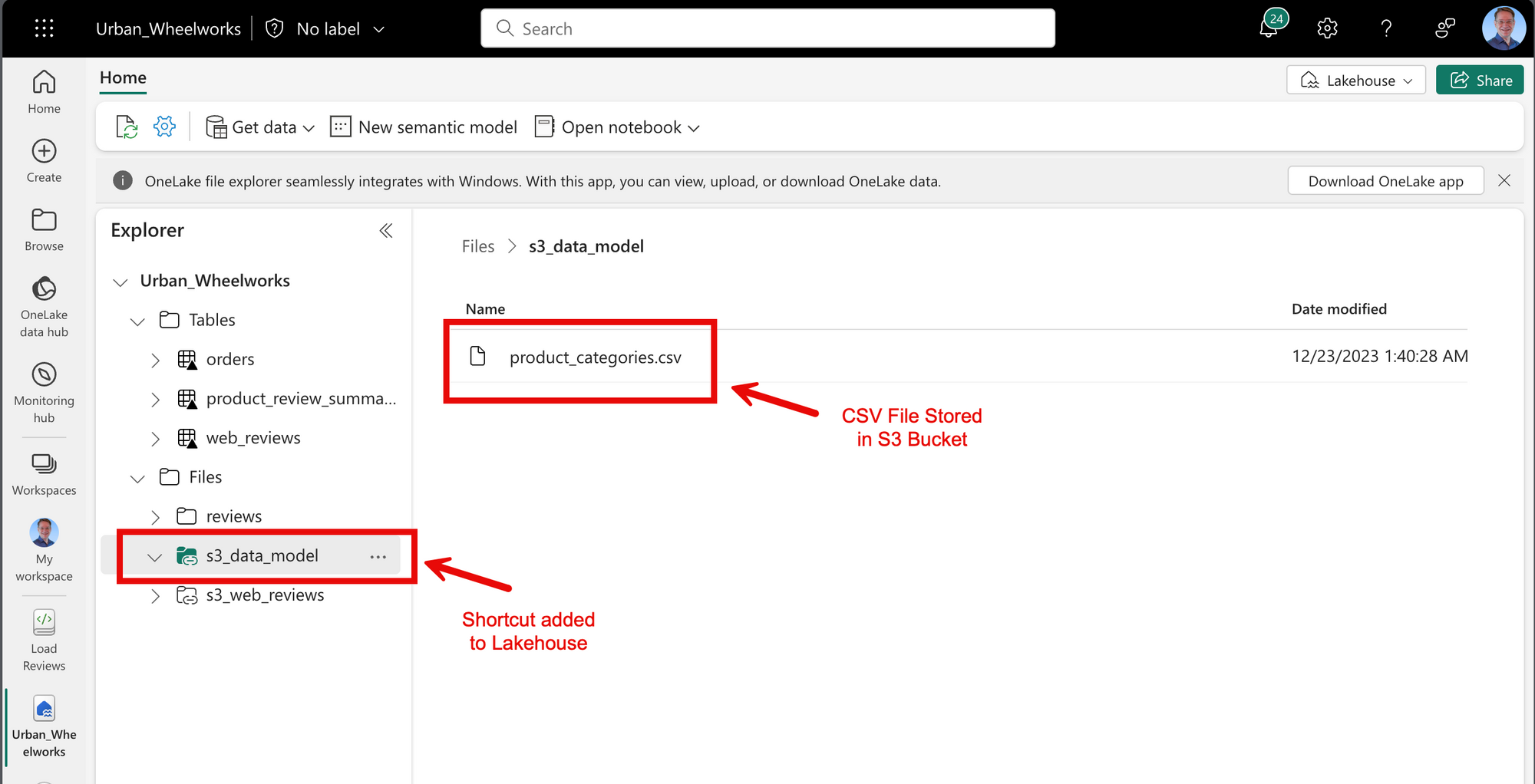
With that end in mind, let's get started!
Create an S3 Bucket
In this post I'll create a new bucket from scratch in AWS. Heading over to the AWS console S3 section, click the link to create a new bucket.
I'll give the bucket a unique name, in this case rhk-shared-bucket. I'll leave all other configuration options as defaults.
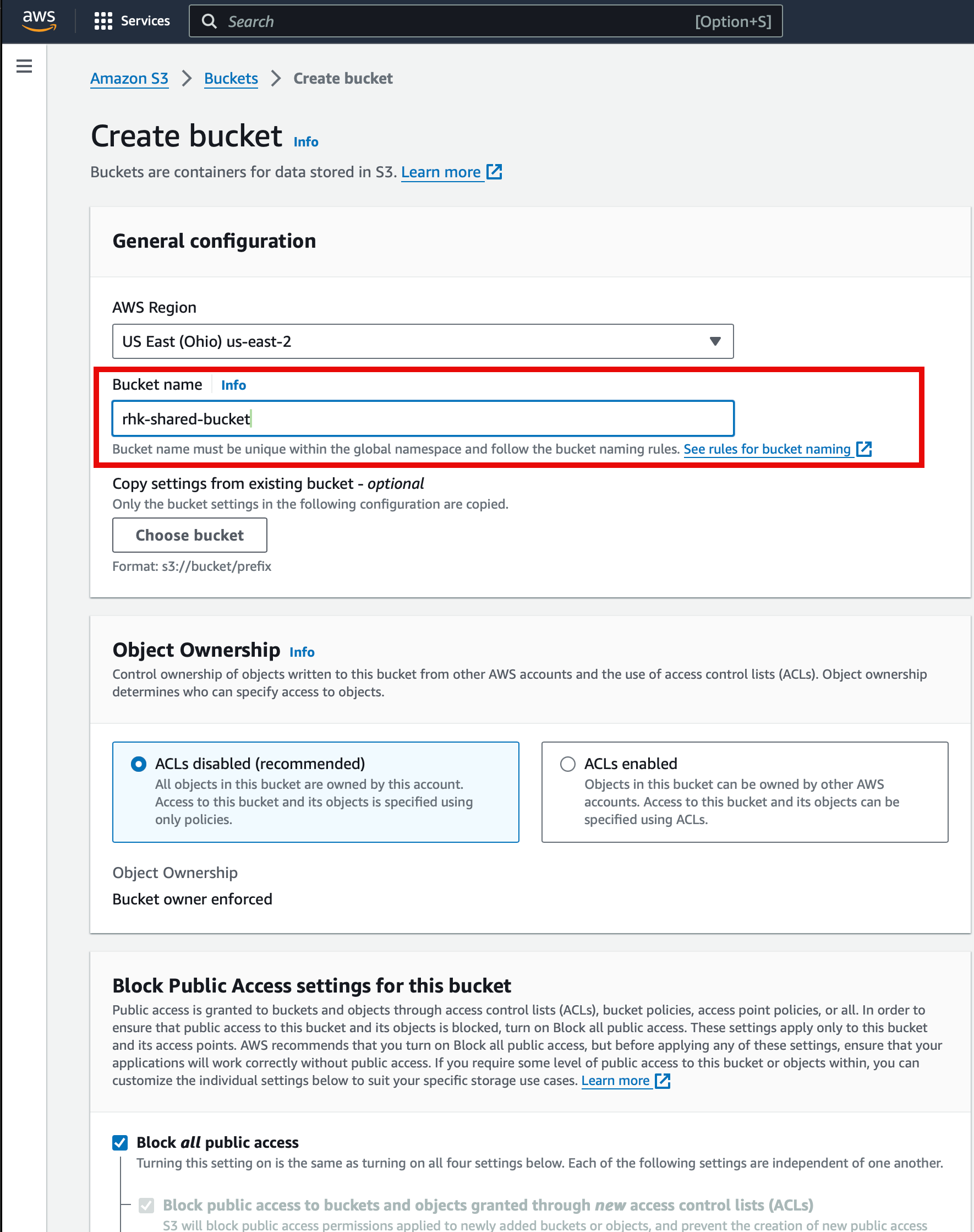
Upload Data to the S3 Bucket
The bucket wouldn't be that useful without some data, so I'll create a folder in the bucket to hold data. In this hypothetical scenario I'll pretend I have a web site running on AWS that drops user review files into the bucket, and I'll ingest them into the Fabric data lake using Spark DataFrames and Python.
After uploading files to a folder in the bucket, I can see them from the AWS S3 console:
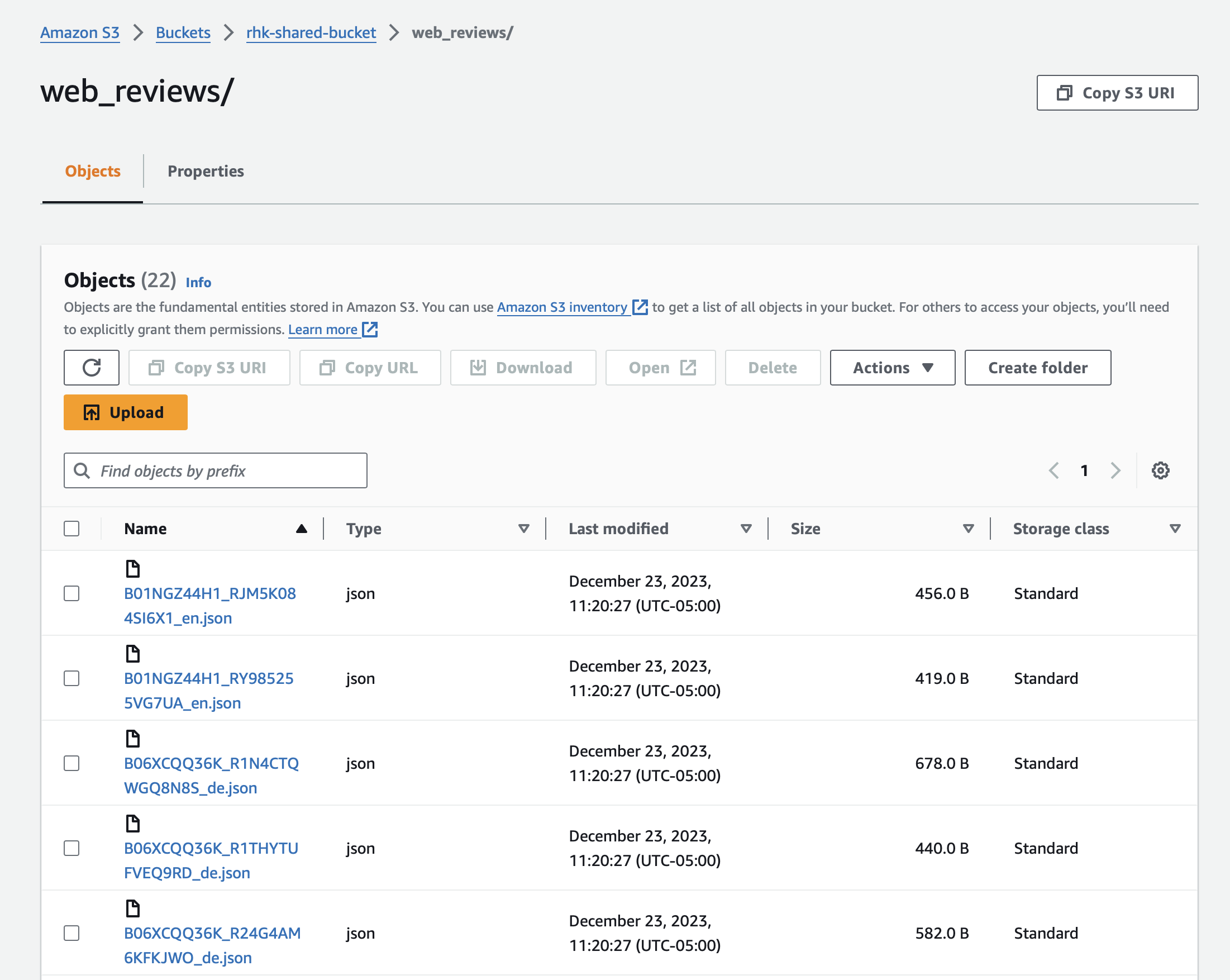
Create a Service Account for Fabric
So far data is in the S3 Bucket, but only AWS administrators can read the files. We want Fabric to read the data, but not leave the bucket open to the Internet. So, let's create a service account for Fabric.
Head over to the AWS IAM Service and create a new user. The user doesn't need any permissions or roles assigned at this time--we'll use a bucket policy to authorize this user to read the S3 bucket later.
When creating a shortcut to the S3 bucket from Fabric, we will need to provide a user access key and secret key.
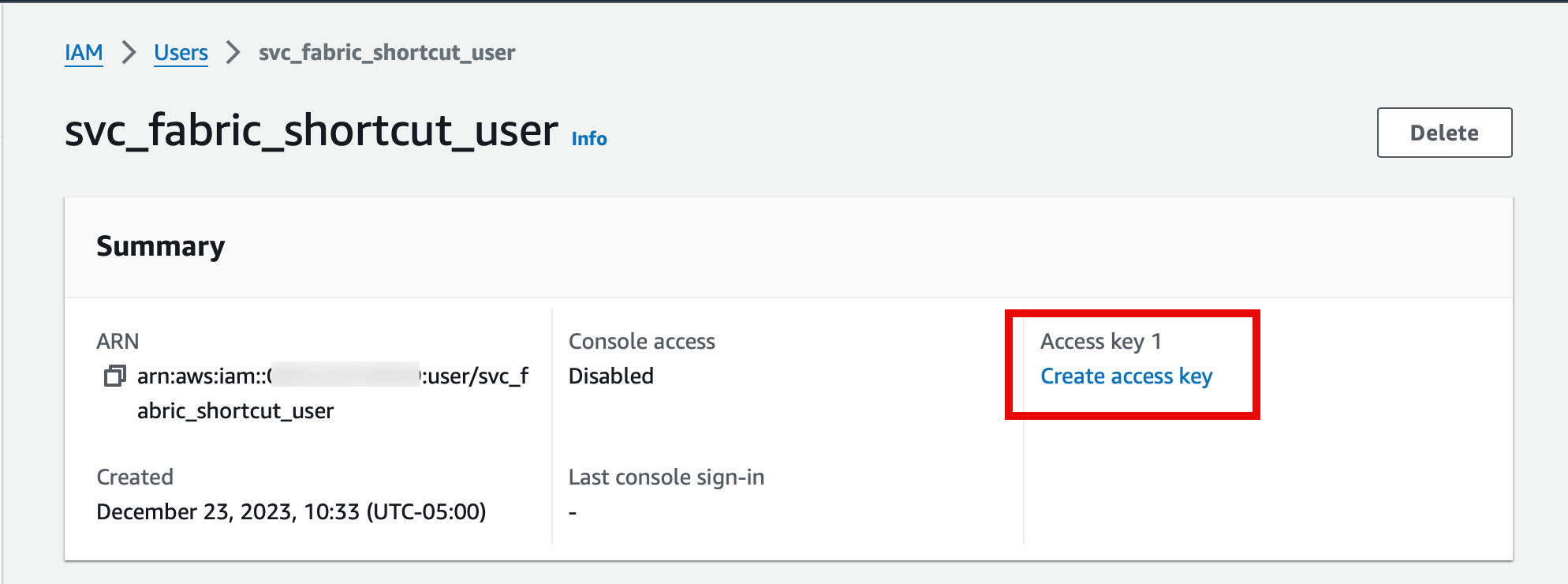
Click on the Create access key link on the new IAM user's summary page to create an access key.
Select the application running outside AWS use case, then press Next.
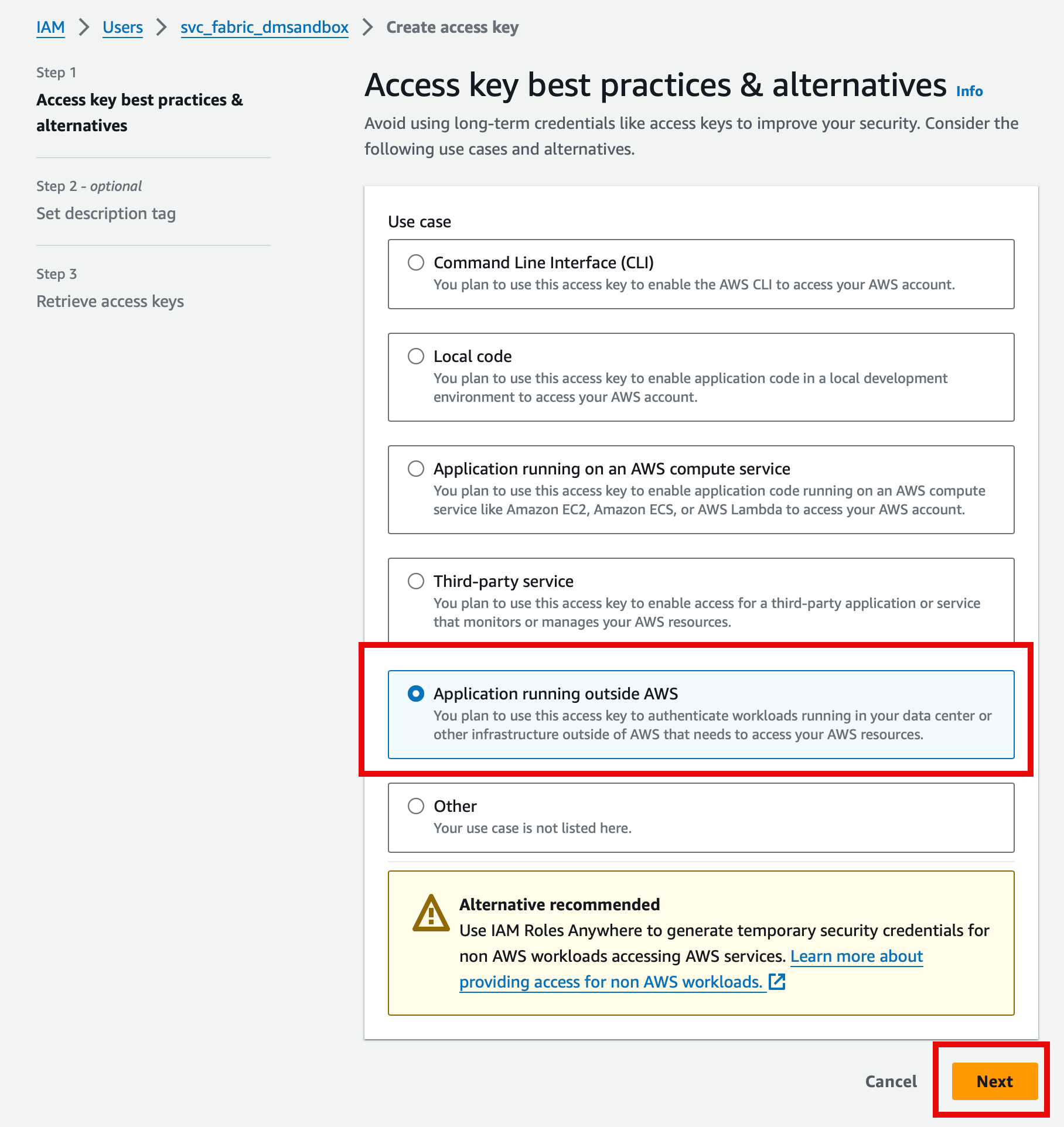
Next provide a description for the key (for reference later)
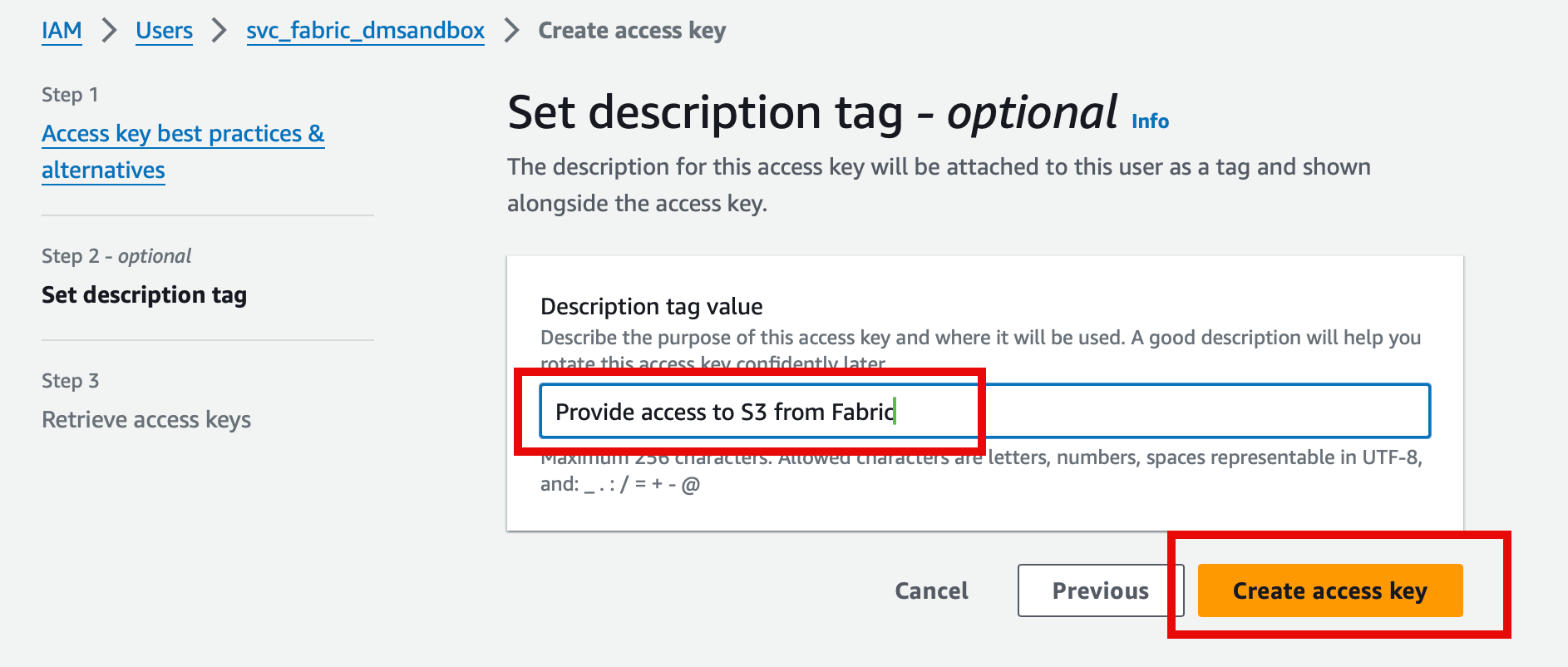
After the Access and Secret access keys are created, copy them and save them somewhere secure. These are two strings we'll need to provide to Fabric when configuring the shortcut.
Add S3 Permissions for the IAM User
Fabric will use the access and secret keys to authenticate to AWS. We need to ensure that the IAM user has permissions to read content from the S3 bucket. In AWS, this is done by adding a bucket policy to the S3 bucket.
GetObject, GetBucketLocation and ListBucket permissions to the target S3 bucket. From the S3 bucket permissions tab, create a bucket policy similar to the following:
{
"Version": "2012-10-17",
"Id": "<a unique ID for the policy>",
"Statement": [
{
"Sid": "<a unique statement id>",
"Effect": "Allow",
"Principal": {
"AWS": "<get the user's ARN from IAM>"
},
"Action": [
"s3:GetObject",
"s3:GetBucketLocation",
"s3:ListBucket"
],
"Resource": [
"<this bucket's ARN>",
"<this bucket's ARN>/*"
]
}
]
}Lookup the S3 URL
When configuring Fabric, we'll need the Internet URL for our bucket. There are multiple ways to discover the URL, but I find a convenient is to copy it from the properties page of a file stored in the bucket.
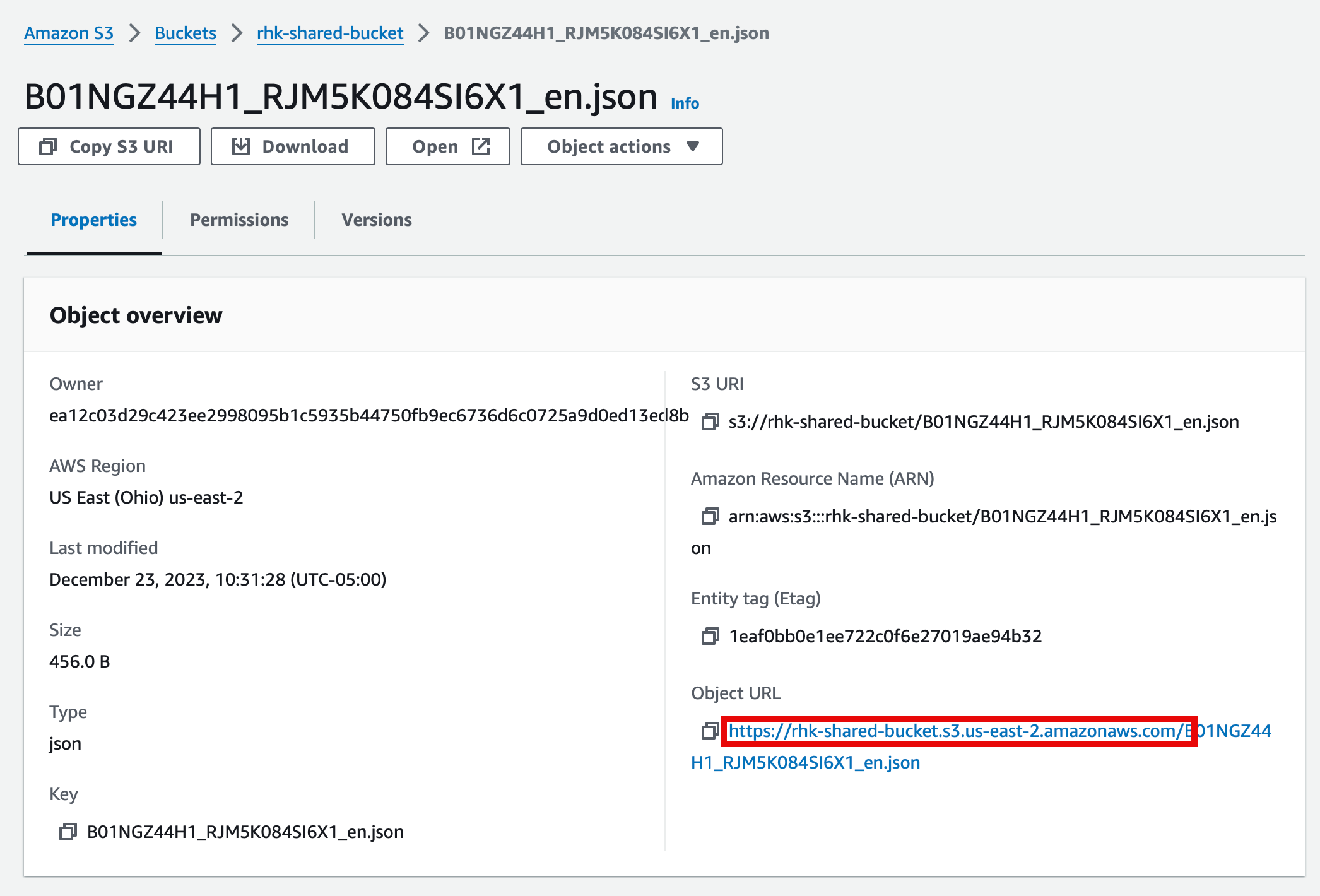
Find the URL and save it along with the secrets created in the last step.
Now that we have data in the bucket, we know the bucket base URL, and have the access and secret keys for the IAM account used to access bucket contents, we can head over to Fabric to create the shortcut!
Add a Shortcut to the S3 Files
Adding the shortcut to Fabric is simple from this point:
- Select the menu option to add a shortcut to the
Filesfolder in a lakehouse - Provide the S3 bucket URL
- Provide the IAM user access key and secret key
- Give the folder within the bucket the shortcut should point to, and a name for the shortcut
Select the Add Shortcut Menu Command
Find the shortcut command on the option menu in the Lakehouse Files folder entry.
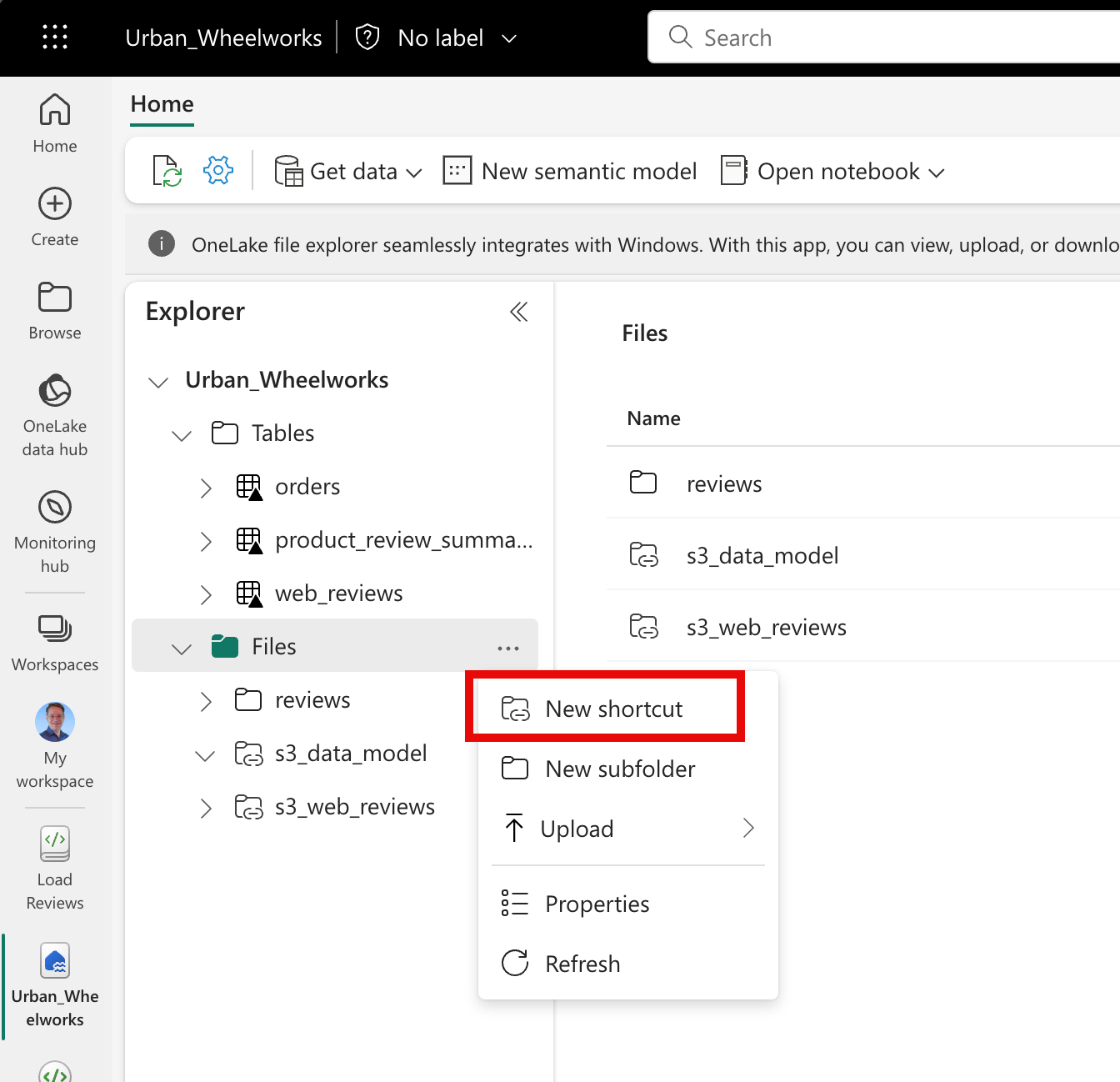
Select Amazon S3 from the External Sources menu
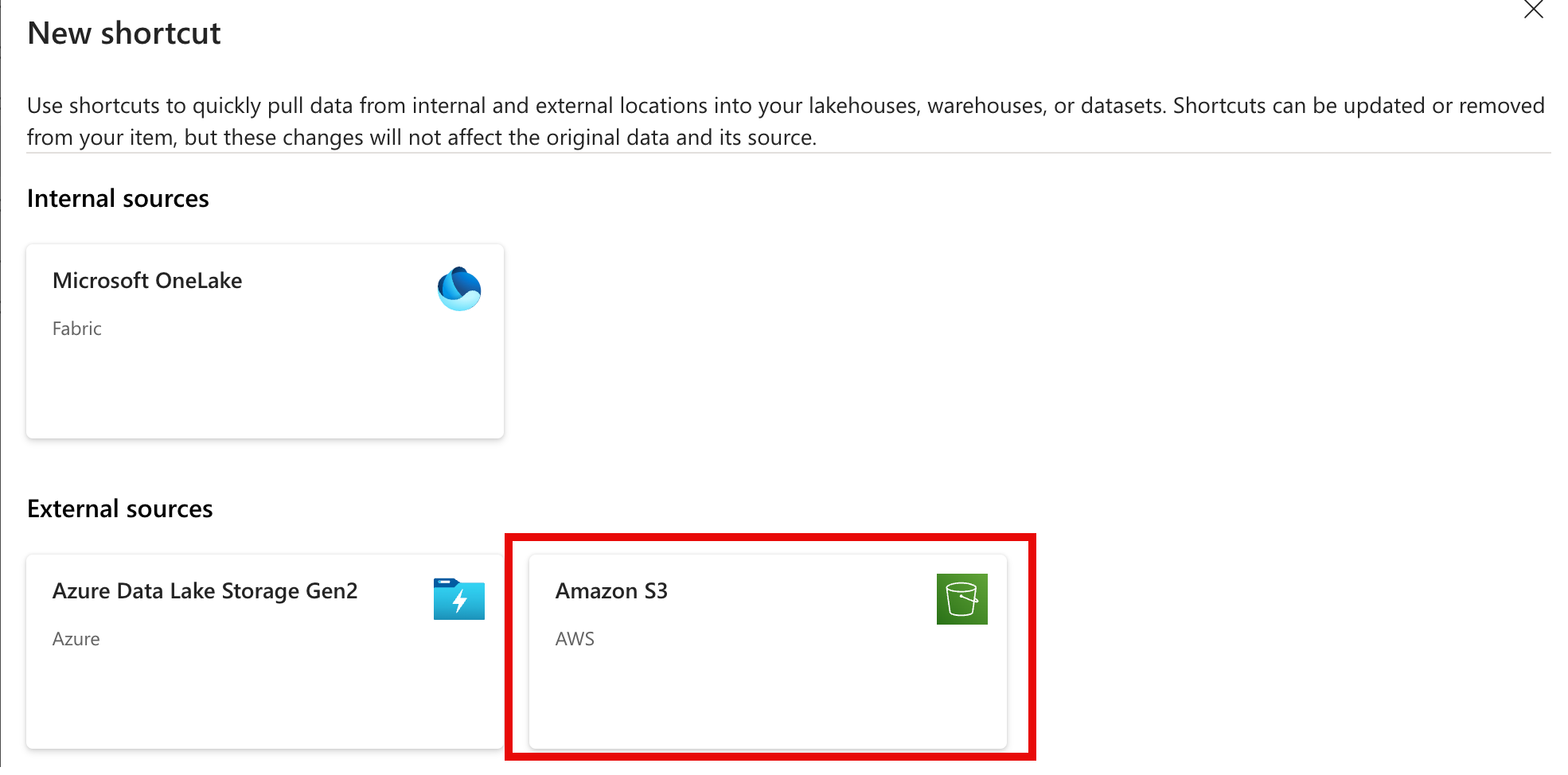
Provide Connection Details
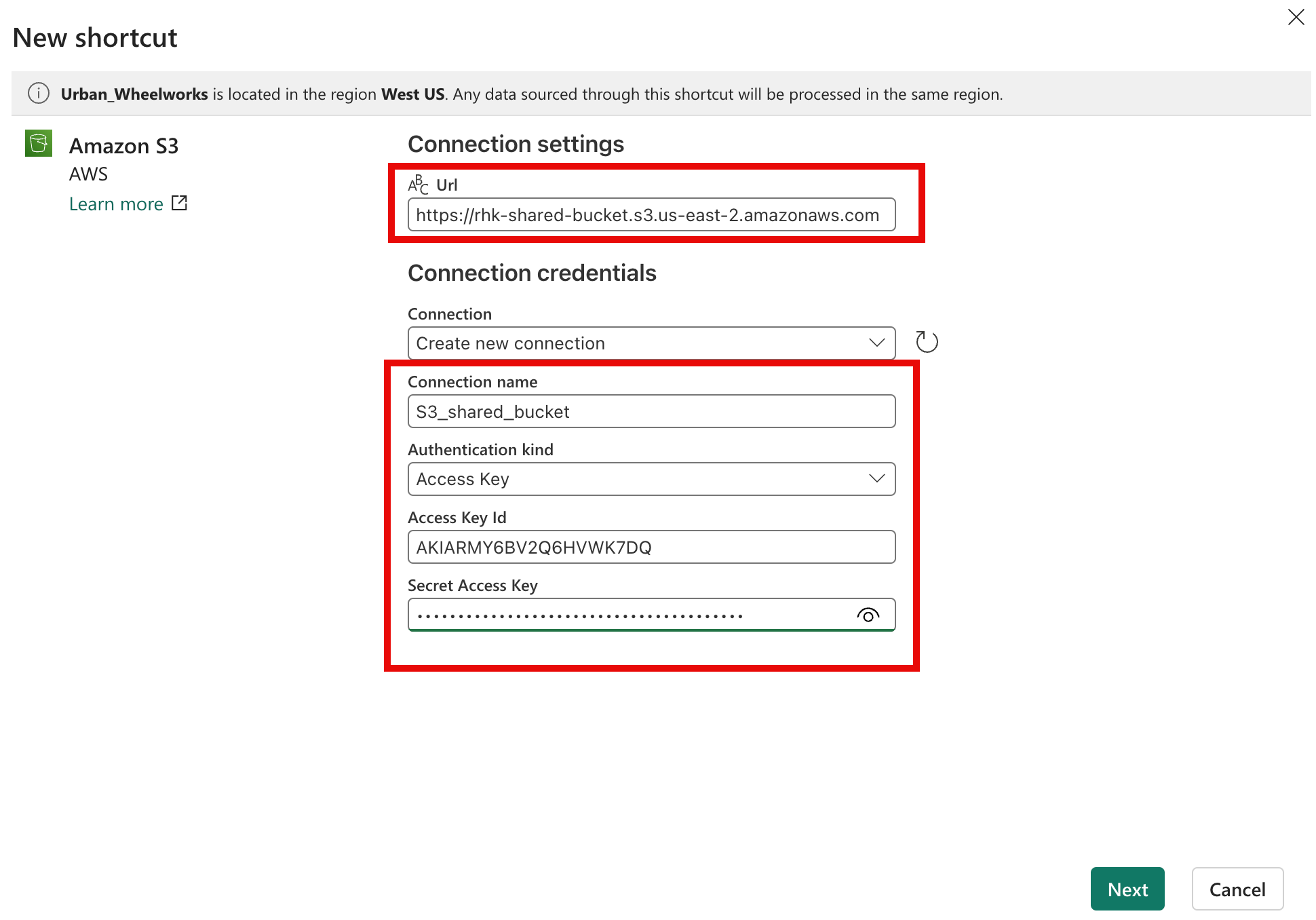
Next we need to create a new connection profile for the S3 bucket. Paste in the URL and keys created in AWS, and provide a connection name to use for future reference.
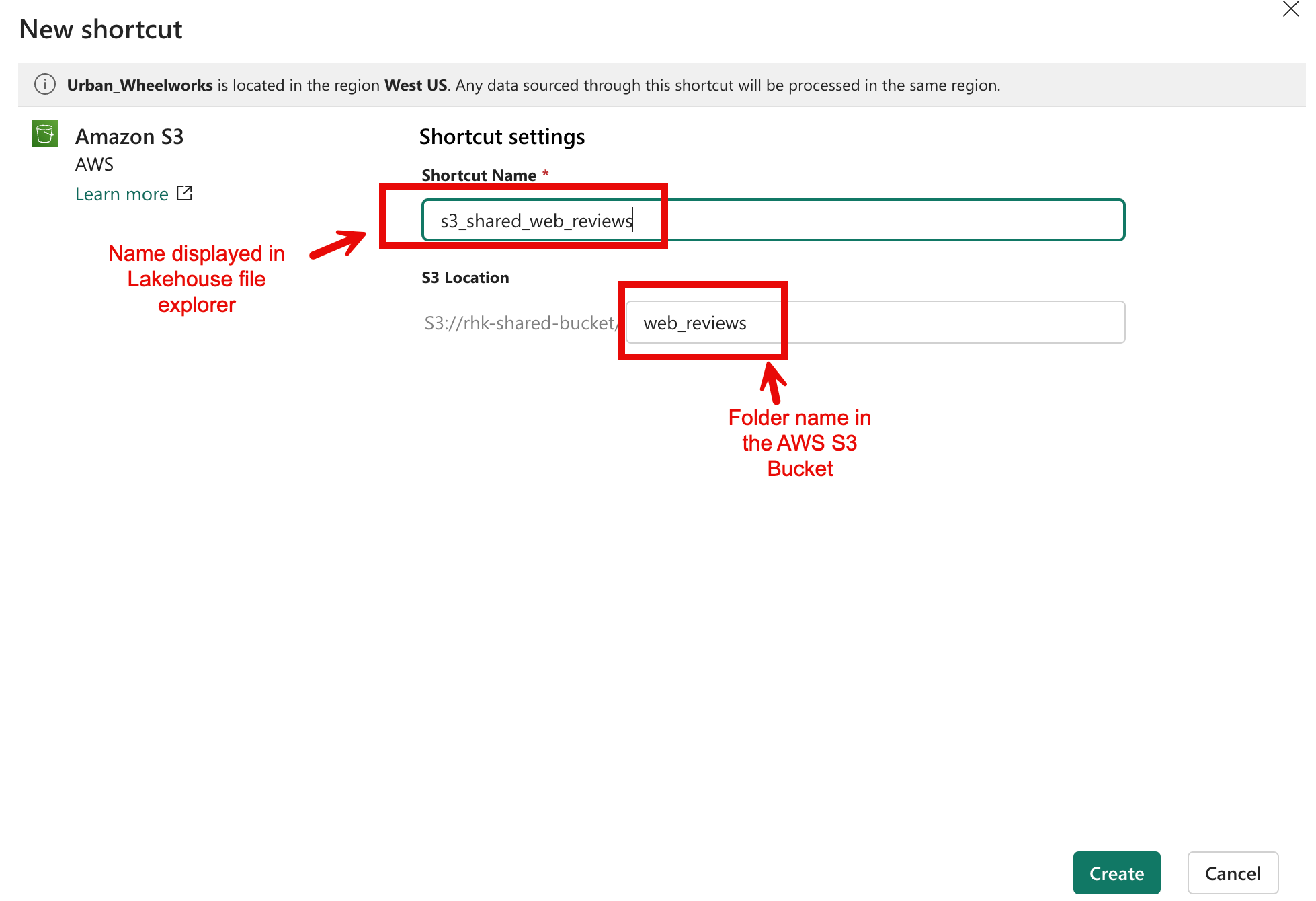
Provide the Shortcut Name and S3 Folder Source
The final step in creating the shortcut is to provide a logical name to display in the Lakehouse browser window, as well as the folder in S3 the shortcut should point to.
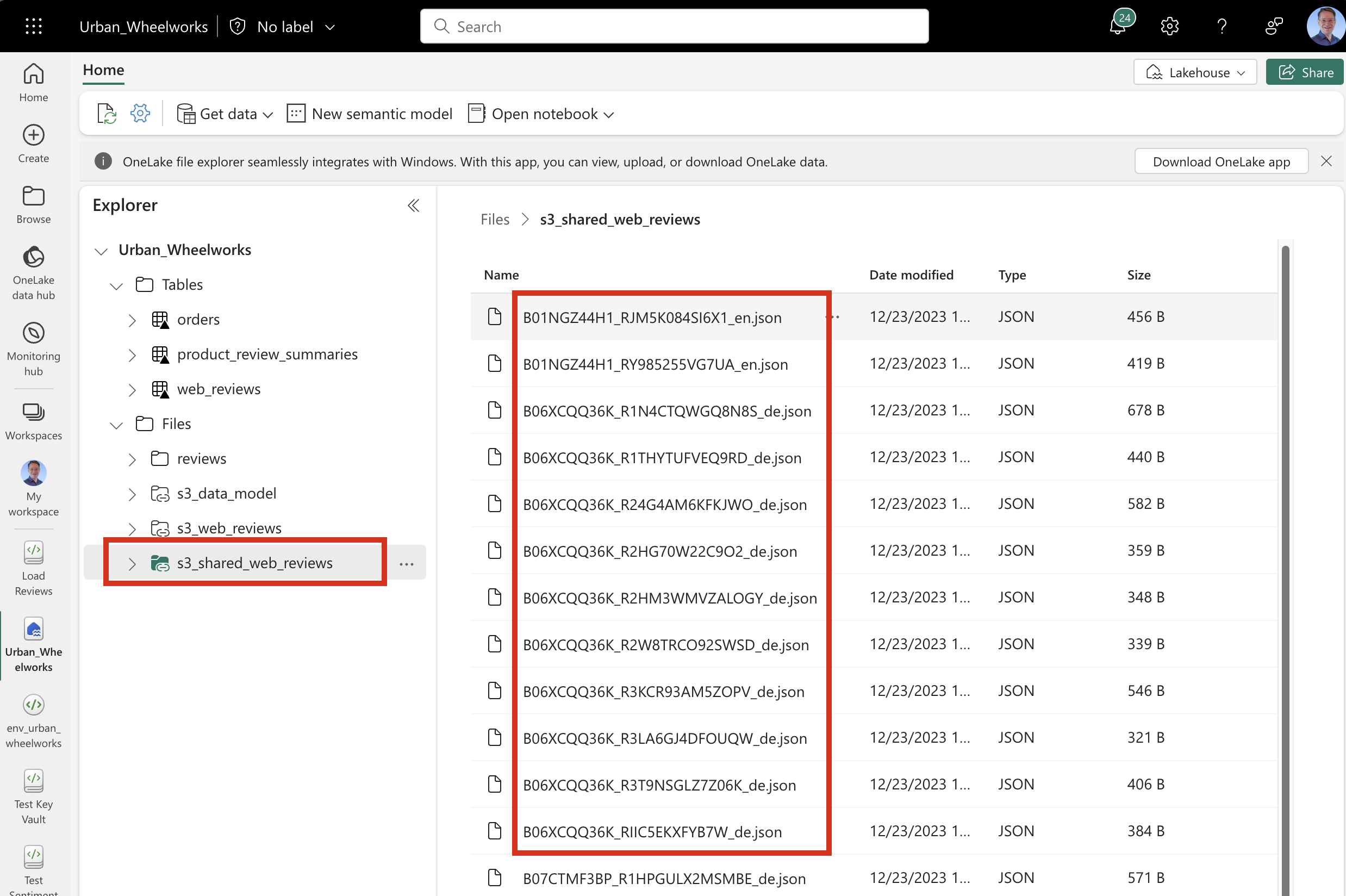
After the shortcut is updated in the file explorer, we can click on it to see the list of files in the S3 bucket.
Test by Reading the Folder Contents into a DataFrame
To test that the shortcut works correctly, we can read the folder contents into a Spark DataFrame.
df=spark.read.option("multiline", "true") \
.json("Files/s3_shared_web_reviews/*")
display(df)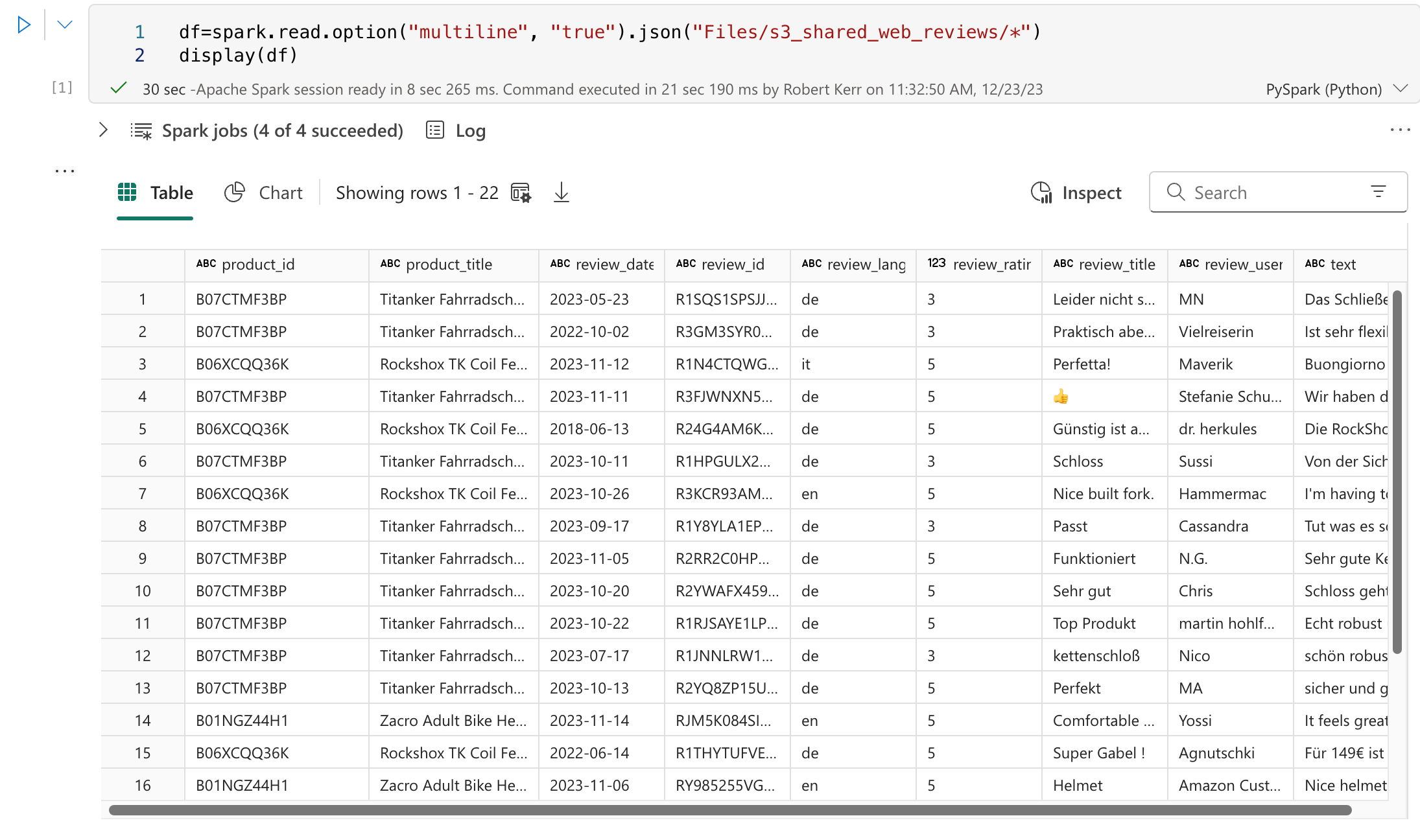
Summary
And that's a wrap. We've created a shortcut from Microsoft Fabric to an AWS S3 bucket, and now we can directly access the data being stored by other applications running on the AWS cloud!
Most importantly, data engineers, data analysts and data scientists don't need to setup pipelines to move data between clouds, since that's being handled for us.