


Large Language Models (LLMs) used by Generative AI solutions are generally trained on public data sets that don't include private data, such as documents and knowledge bases private to our own organizations.
This post is a walk-through of using a Microsoft OpenAI Service model along with a Retrieval Augmented Generation technique, which Microsoft calls Use Your Data.
Video Walk-Through
This post is accompanied by a walk-through video, which demonstrates the technique in an interactive format. The discussion and text walk-through continues after the video.
What's RAG?
Retrieval Augmented Generation (RAG) is a common technique used to "teach" Large Language Models how to correctly answer prompts that require organization-specific data.
Unlike Model Fine-Tuning, RAG doesn't require training of the underlying LLM (or even targeted parameter tuning). Because fine-tuning of LLMs can be expensive and time-consuming, techniques like RAG that can guide the LLM to an appropriate response without a training step are very economical.
With RAG techniques, we first use a knowledge base (or application integration) to fetch knowledge or data specific to the question in the prompt and pass it to the LLM along with the prompt. The LLM then uses the augmented data to formulate its response.
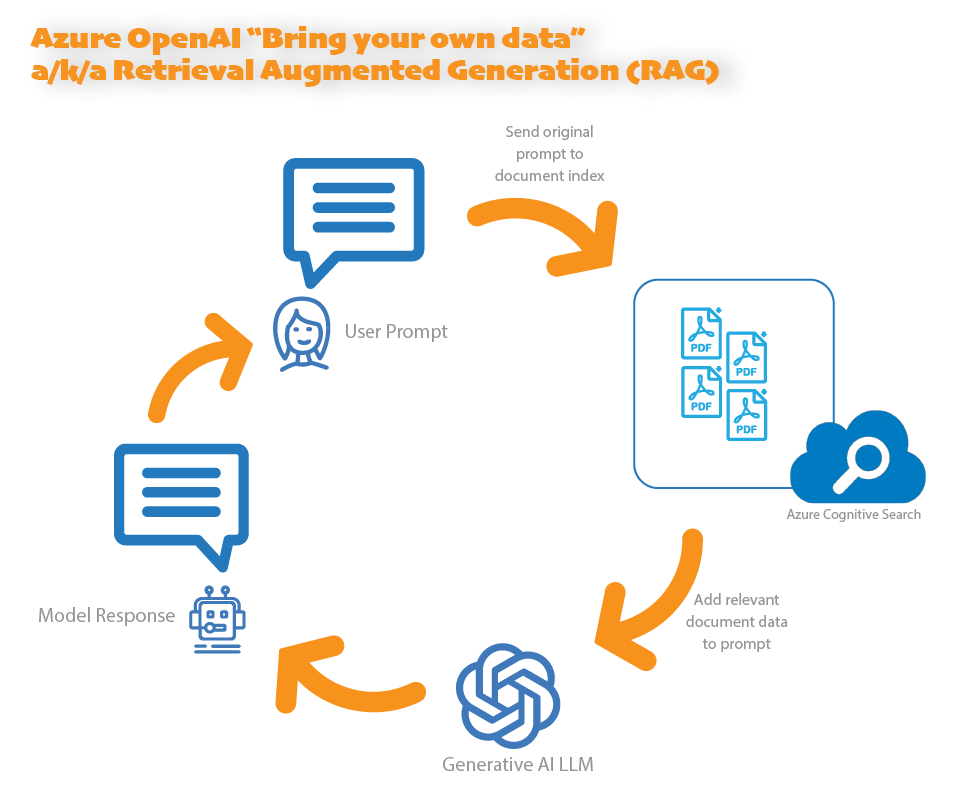
Microsoft's 'Bring Your Data' Feature
Microsoft's Bring Your Data approach uses its Azure AI Cognitive Search engine as an index of data to use in the augmentation step. Cognitive Search can index many kinds of data. A common approach when implementing RAG with OpenAI Service is to index documents, such as PDF or Word documents.
In this walk-through, we'll use Cognitive Search to index a collection of PDF files, enabling users to ask questions that can be answered by using the information contained in the PDF files.
Let's Implement it!
Now let's test the Bring Your Data feature by creating an OpenAI Service deployment that references custom PDF files. The files we'll add are:
- A collection of FAA Emergency Airworthiness Directives from 2020 - 2023.
- Flight Crew Manuals and maintenance documents for several jet airplanes, including the Boeing 747, Learjet 45 and Challenger 300.
- Maintenance procedures for several airframes.
These documents aren't included in public Generative AI LLMs, as the documents were extracted from specialized data sources not included in LLM training data sets. This is similar to a business solution that uses Generative AI that includes private, internal documents or data.
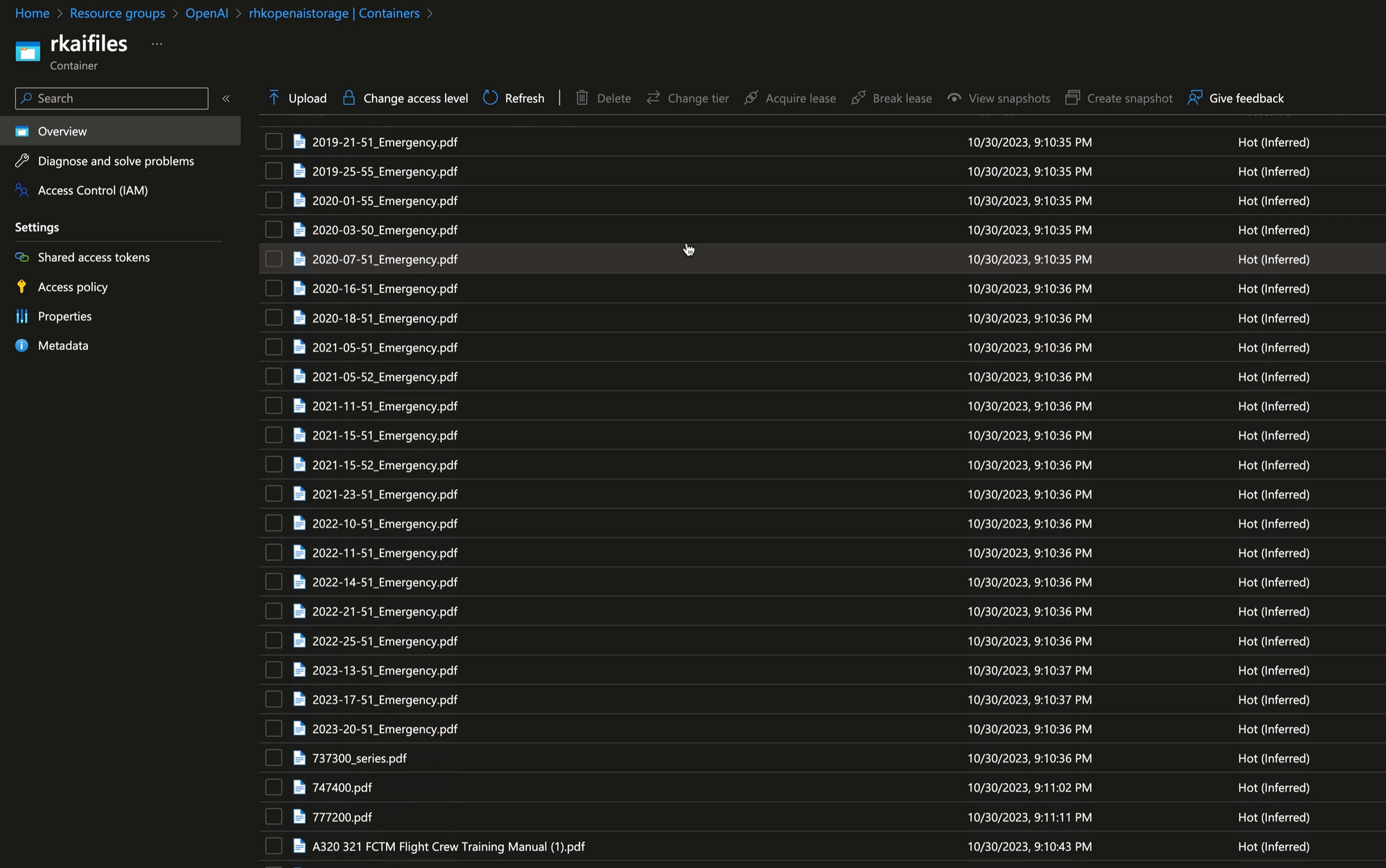
Uploading Files
The first step in using data in prompt augmentation is to add data to the Cognitive Search index. In this case we'll upload the set of files containing technical information relating to the maintenance and operation of commercial aircraft.
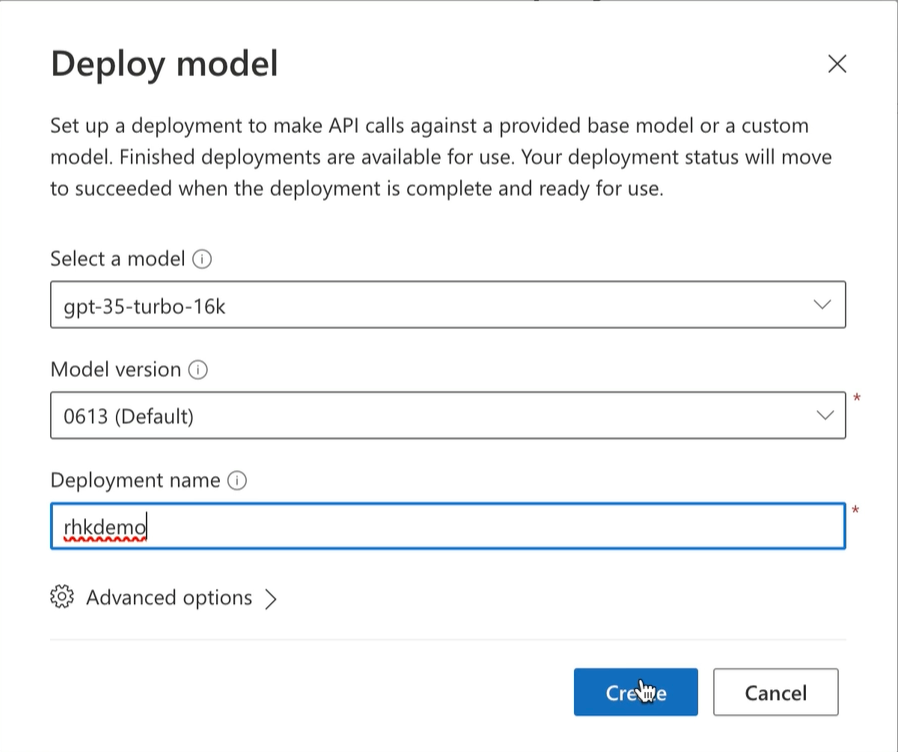
Creating an OpenAI Deployment
With the files available in an Azure storage container, we can go ahead and create the OpenAI deployment. In this example, we'll use the gpt-35-turb-16k model.
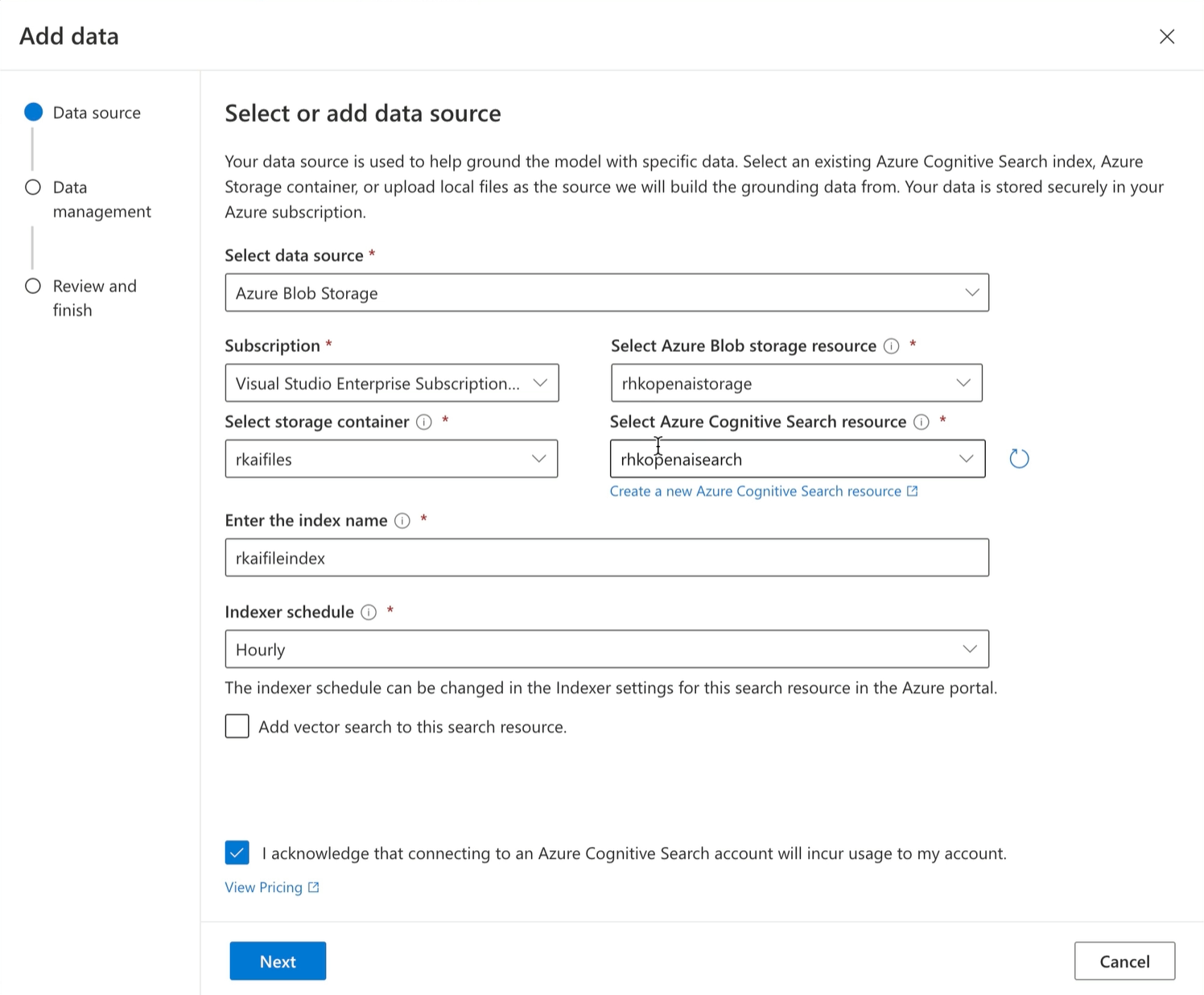
Create a Cognitive Index with the Deployment
As we create the deployment, we can also create a new Azure Cognitive Search index to use for retrieving augmented knowledge during prompt submission. The nuts and bolts of pre-processing prompts by searching the index are handled internally by the OpenAI Service, so we don't need to implement the pipeline step-by-step.
Testing the Deployment in the Sandbox
Within the OpenAI Studio, we can immediately check whether the OpenAI Service is finding relevant knowledge in Cognitive Search for prompts relating to the uploaded PDF files.
To test, we'll ask a question directly related to one of the FAA Technical Service Bulletins:
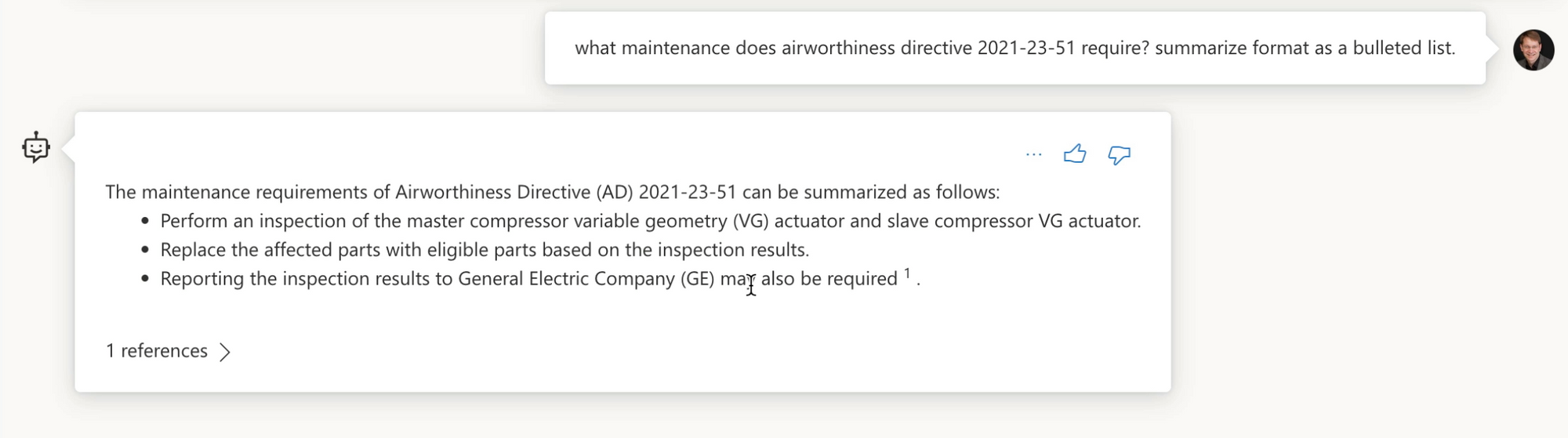
As we can see, the response includes information in the service bulletin--summarized and concisely formatted as requested!
Testing the Deployment in Python
While testing in the sandbox gives us confidence that the responses are as expected, let's look at how this deployment can be used from custom application code. For this demo, we'll create a Python application, and call the deployment using the openai python SDK
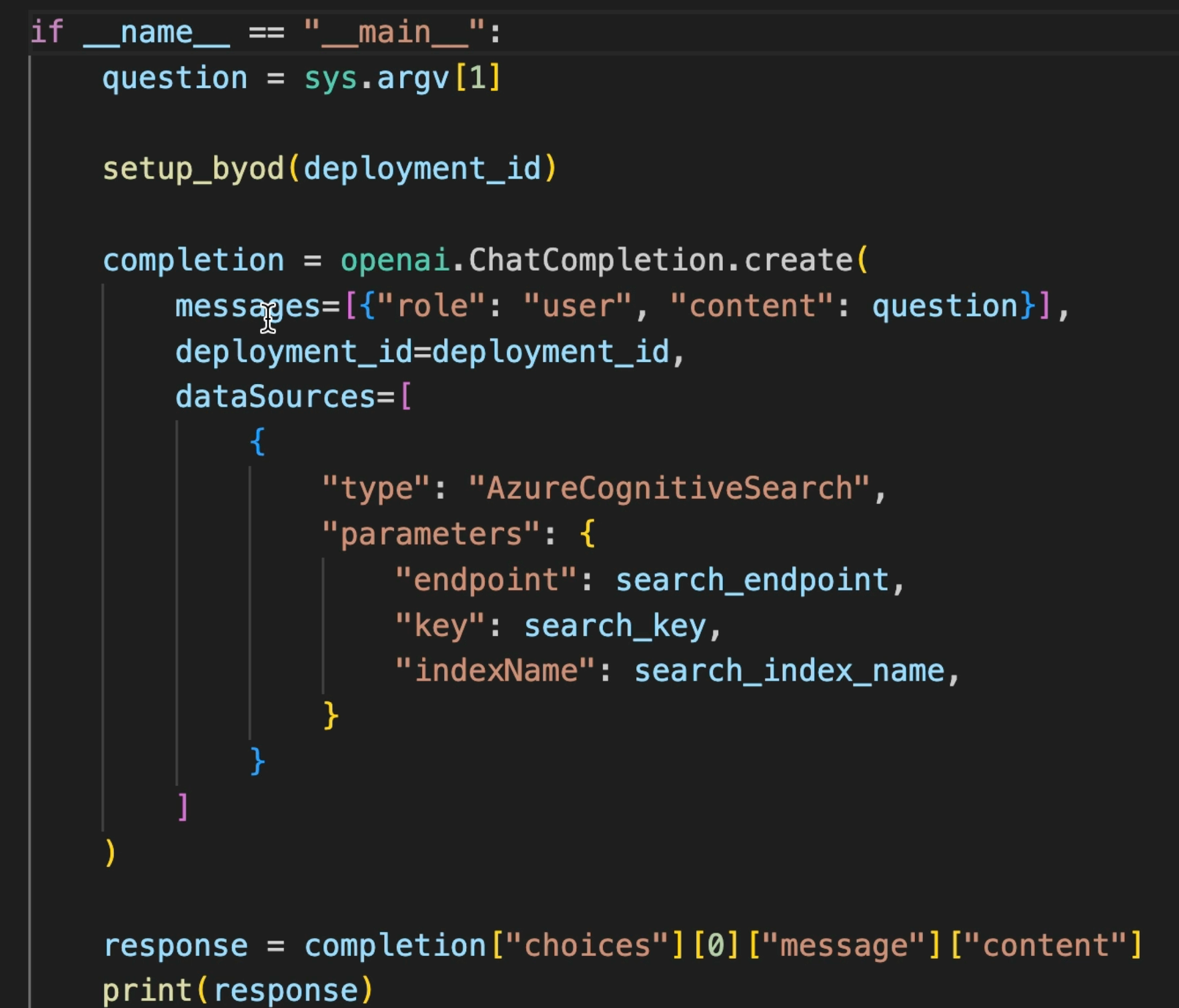
Calling the Service
We then call the deployment endpoint using the openai SDK CALL NAME object. Note that when forming the prompt object, we specify the Cognitive Search index to use for knowledge augmentation.
Test the Python App
To test the Python code, we can call the app from the command-line, passing in the prompt. The Python code will call the service endpoints in Azure, then output the text of the response.
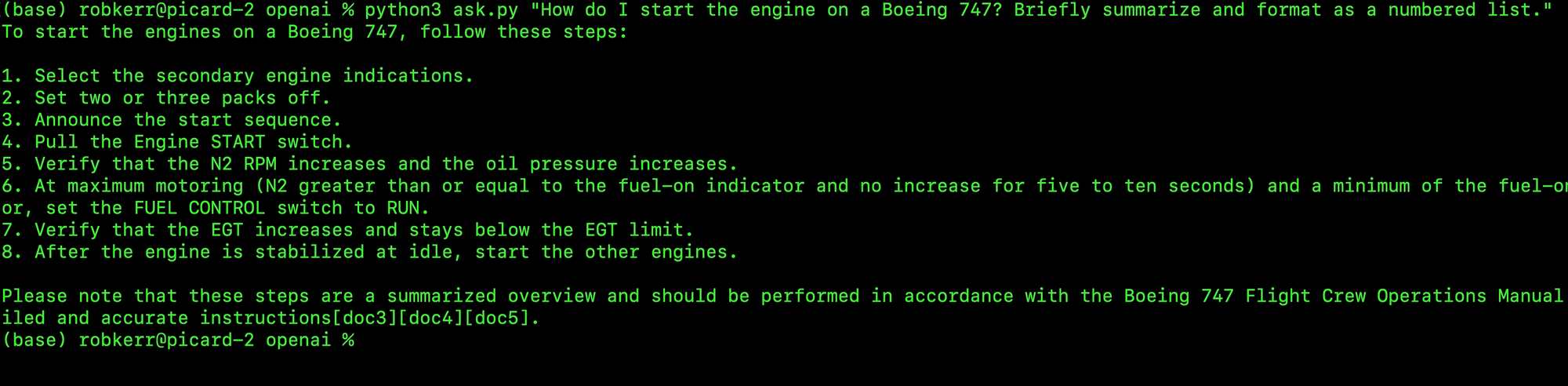
First, we repeat the same test as done in the sandbox:

Then we'll try a new question, how to start the engine of a Boeing 747?
Summary
To use Generative AI in custom solutions, some form of prompt engineering, model tuning, or prompt augmentation is usually necessary. While model fine-tuning may be warranted in some cases, it can be expensive and less flexible than prompt engineering or RAG techniques.
For many business solutions, where returning private knowledge using Generative AI techniques is a requirement, RAG techniques such as Microsoft's Bring Your Data feature in the Azure OpenAI Service are an effective technique that has a relatively low development and operating cost.




