


The integration of generative AI with traditional data management and analytics opens new opportunities to provide value and insight that were difficult to achieve in the past.
One technique for leveraging generative AI technologies in data analysis is to use AI to generate summarizations of content. This type of summarization is an ideal use of generative models like OpenAI GPT.
In this post we'll walk through a solution that leverages Azure Open AI Services to summarize customer product reviews logged to a web site to provide managers and data analysts a product-level sense of how customers feel about products.
Video Tutorial Available
The balance of this tutorial-orientated post is available in video format on YouTube using the following embedded video. The rest of the text walk-through continues after the embedded video.
Creating an OpenAI Service
The first step in the process is to create an Azure OpenAI studio deployment. In this solution an existing Azure OpenAI services instance is created. The service establishes a specific API endpoint for our solution, creates a container for specific deployments, creates authorization keys, and serves as an anchor for GPT token billing.
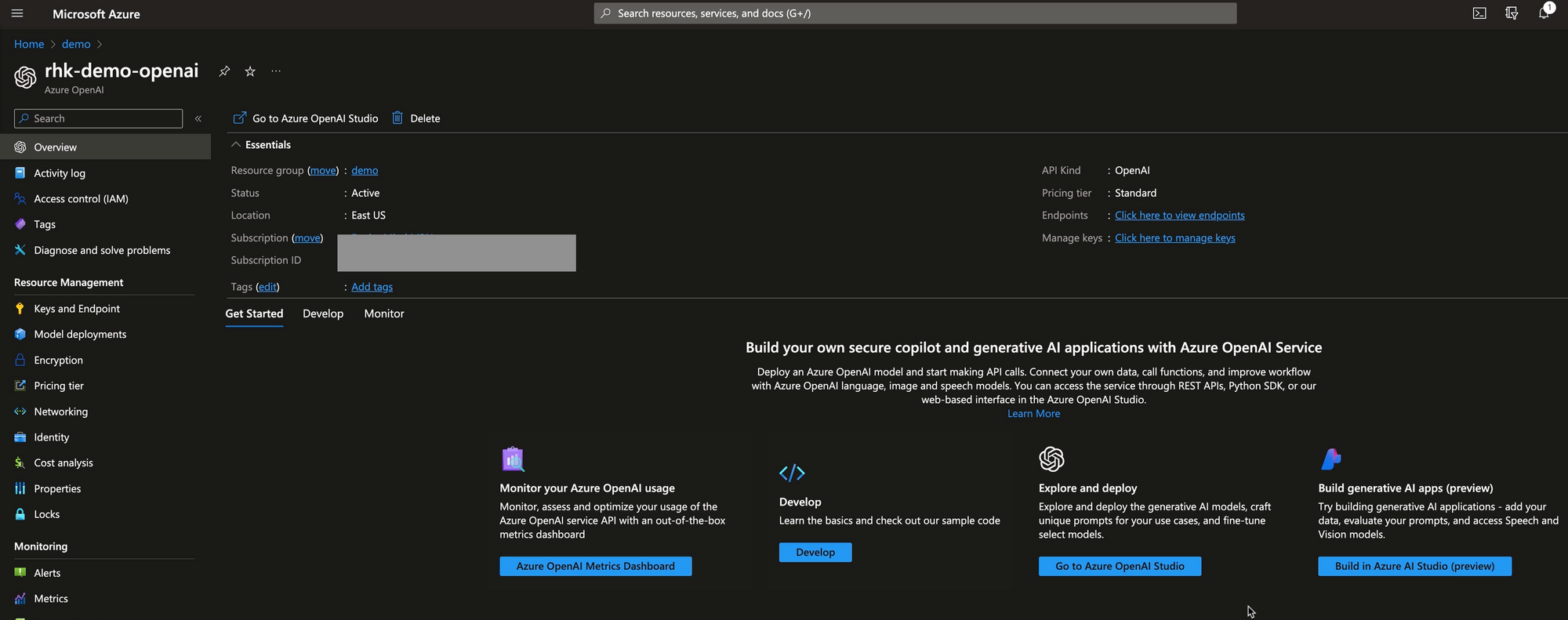
GPT Model Deployment
Within the Azure OpenAI Service instance, we can deploy models. For this solution, I've deployed a deployment of the gpt-35-turbo-16k model. Deploying a model creates an endpoint that specifies which model version we'll use and defines the token quota (the maximum rate at which requests can be made).
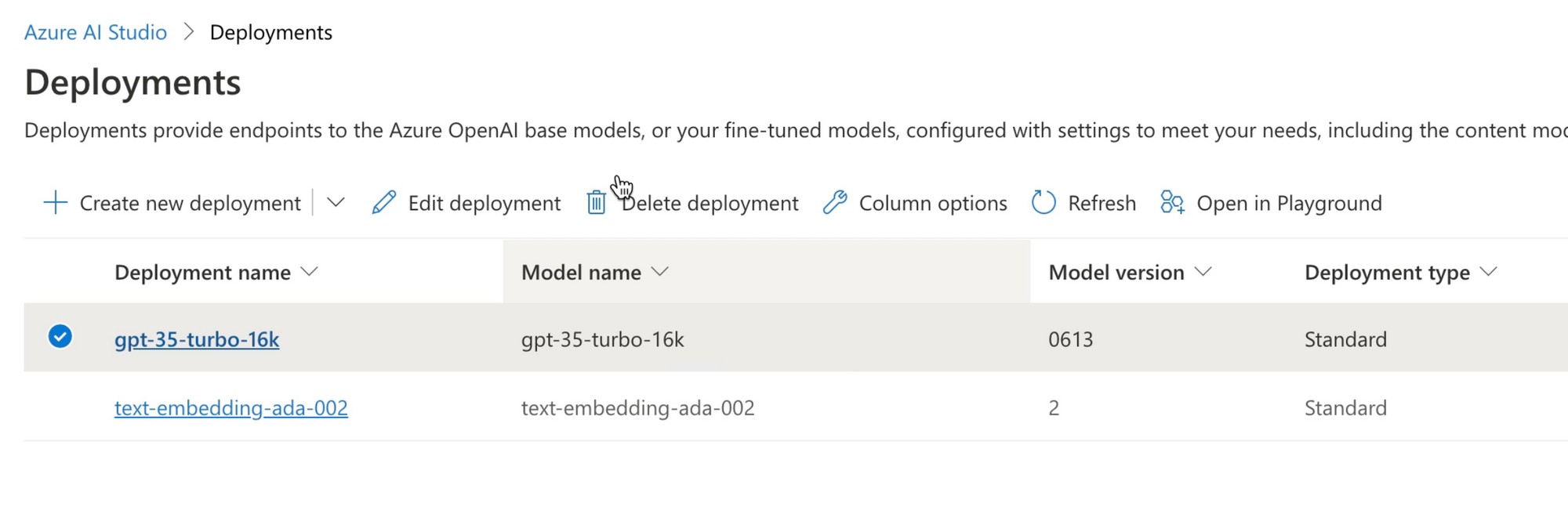
In the Fabric solution, we'll need the deployment name (gpt-35-turbo-16k), as well as the endpoint for our Azure OpenAI Services service, and one of the API keys which authorize applications to use the OpenAI Service.
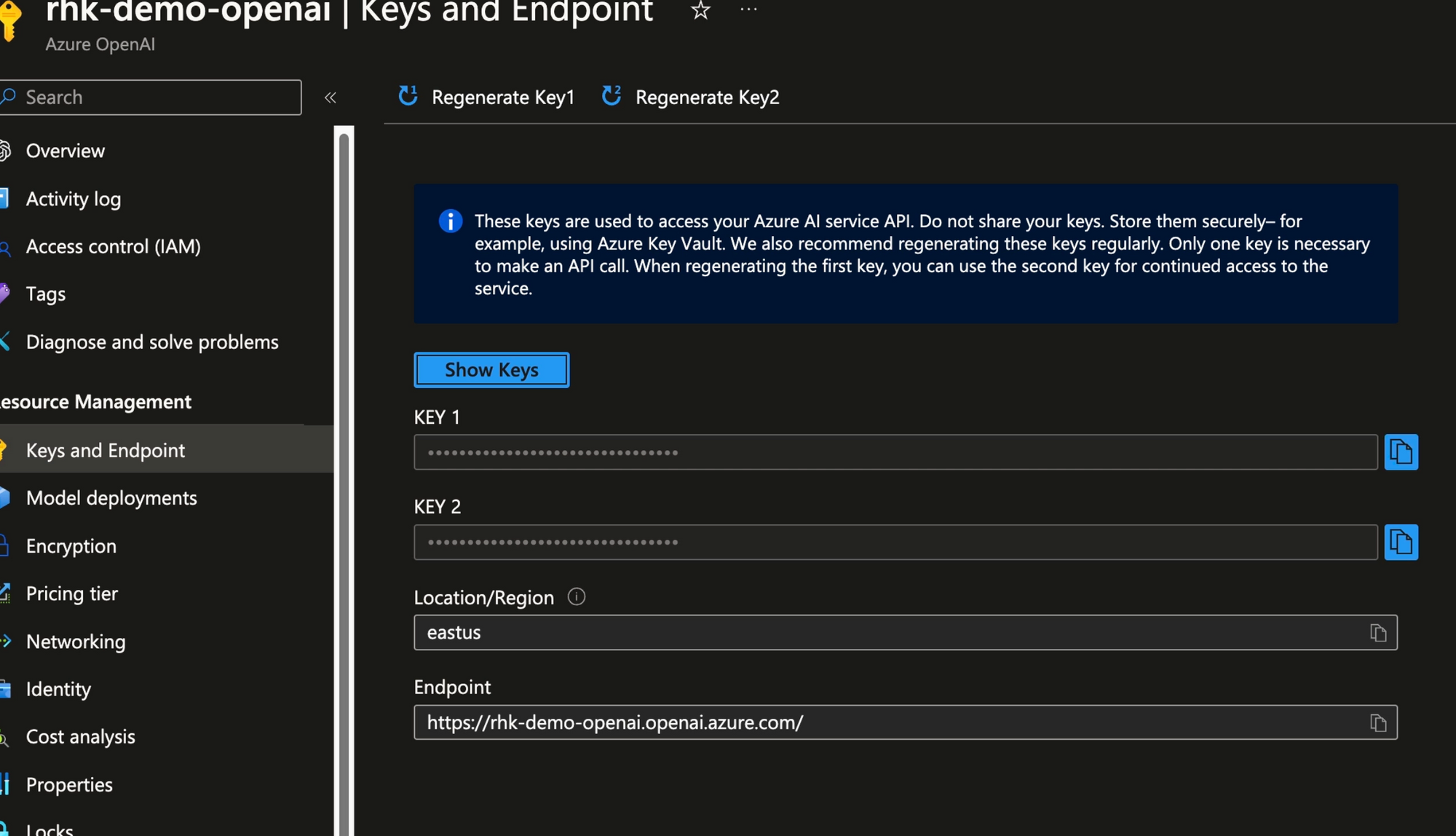
Azure Key Vault
As a best practice, store keys in Azure Key Vault. Key Vault provides underlying keys to requesting processes based on authorization granted by Azure Entra ID. The key is copied from the above screen and added to a Key Vault. Later in Fabric, we'll import the key from the vault as the Notebook runs.
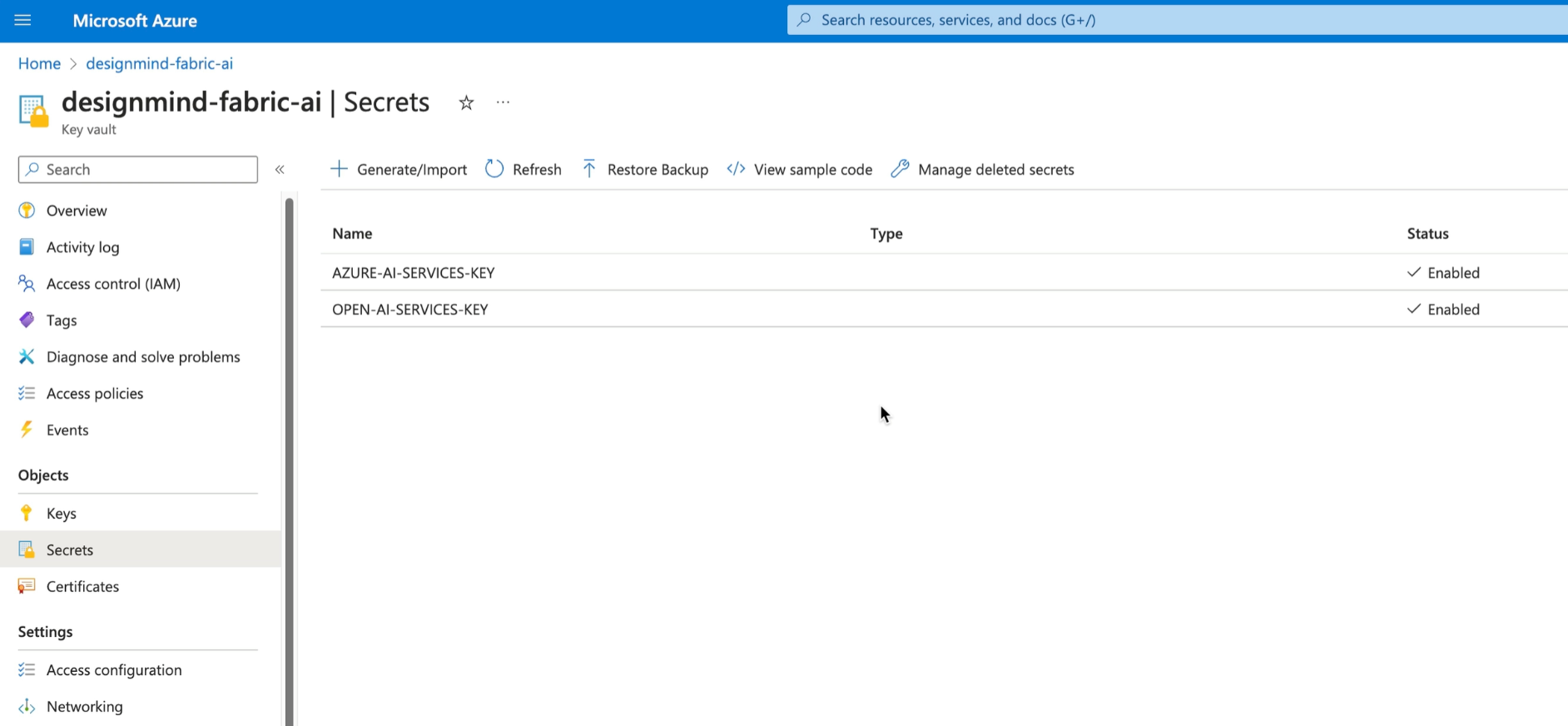
If you're not sure how to use Key Vault, refer to my Azure Key Vault cheat sheet!
Let's Code that Notebook!
Now that we have an OpenAI Services deployment ready, and have put the authorization key in the key vault, we're ready to start building the solution in Fabric!
Review the Input Data
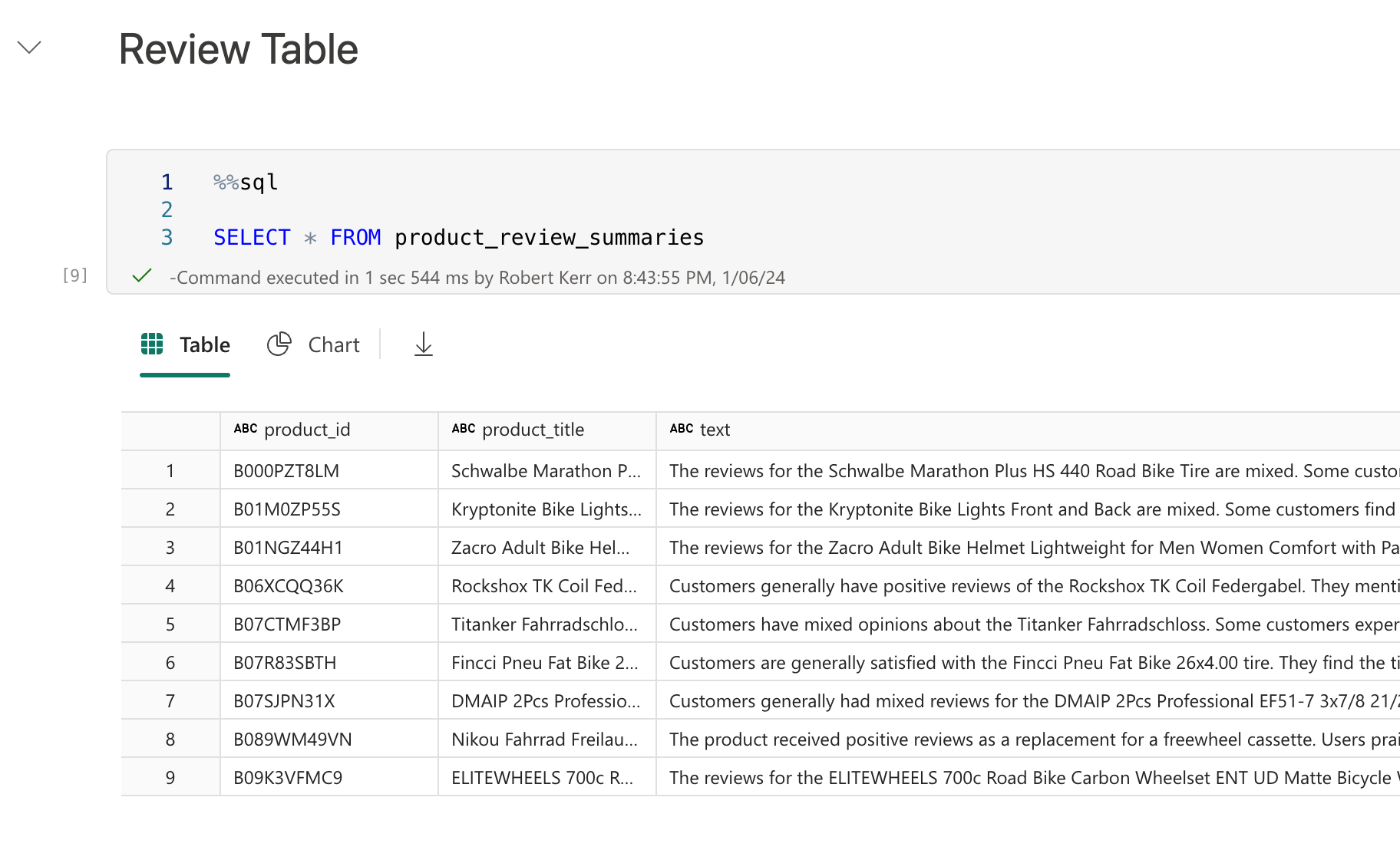
In this solution, we start with a Delta table in a Fabric Lakehouse containing the text of every customer review. Each review is keyed with an associated product id and product name--but our users would like to have a high-level overview of commonalities in reviews. We can use a Large Language Model such as GPT to easily create this type of summary!
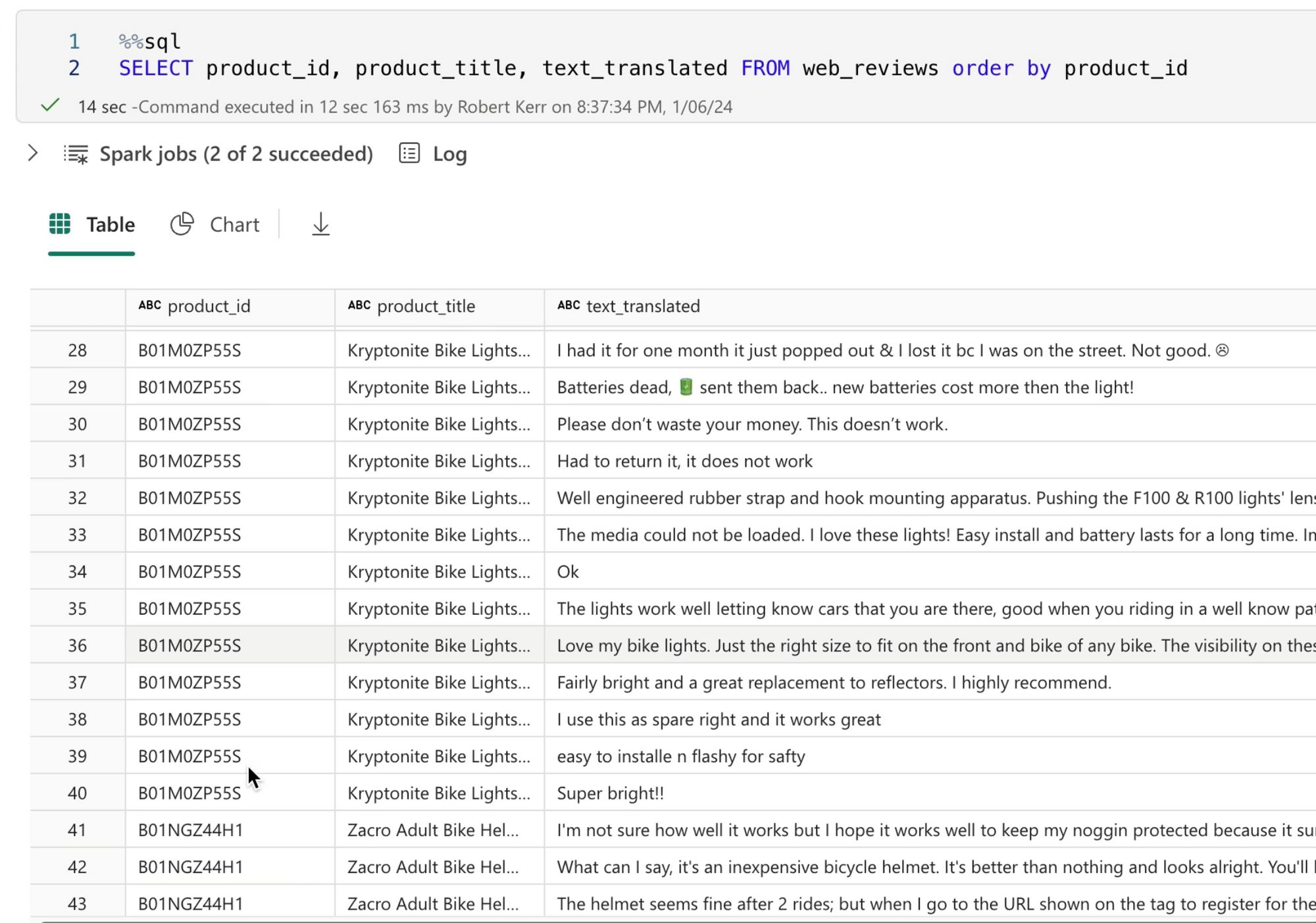
Author the Notebook
In this solution I've created a notebook in the Synapse Data Science workload called Generative_AI_Summarization, and connected the notebook to the Lakehouse containing the original reviews.
Fetch the OpenAI Services Key
We need the OpenAI Services key within the notebook, so as a first step we'll gain access to the key and store it in a variable accessible to the notebook's spark session.

- In line 2-3, we import the
PyTridentTokenLibraryprovided by Fabric to provide access to Azure Key Vault. - In line 12 we call the
get_secret_with_tokenmethod to fetch the secret from the vault and assign it to the variableopenai_services_key.
Even though the key is stored in a session variable, it's still protected from unauthorized disclosure and/or storage in a Git repository. The notebook knows the return from get_secret_with_token is sensitive information and won't display it within the notebook.
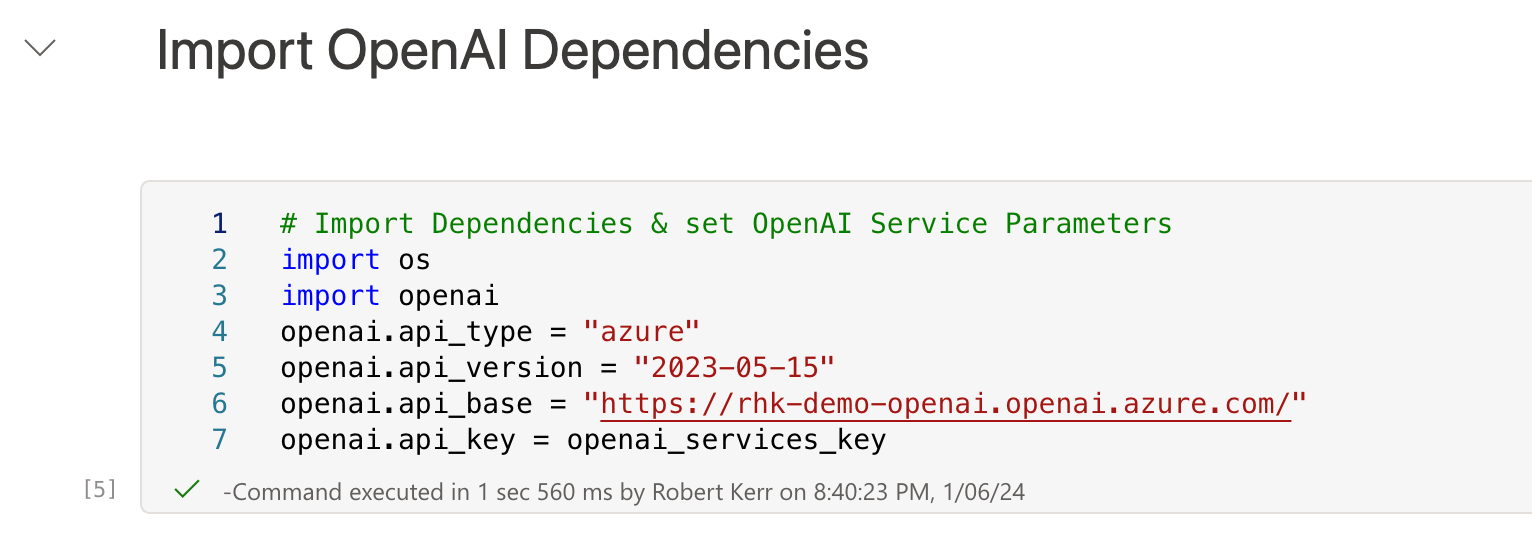
Initialize the OpenAI SDK
Next, we'll import the openai SDK and provide authorization information to it. This is the point where we use the deployment information and security keys we created in Azure OpenAI Services in previous steps.
Generate Summaries
Now for the exiting part – calling OpenAI GPT to generate summaries!
The following code does the following:
- Uses Spark SQL to generate a list of products contained in a table
web_reviewsthat have user reviews available (see the table content above). - For each product, fetches the text of all available reviews.
- Creates a GPT prompt asking the large language model to provide a single summary that encapsulates the consensus of all reviews.
Here's the code, with a description of key elements below:

- Lines 4-8 define the structure of the output row for a product review summary.
- Line 11 creates an empty array. Each product-summary review will be added to this array with the schema defined in the
schemavariable. - Line 14 fetches a list of products that have reviews available as a Pandas DataFrame.
- Line 17 begins an iteration over the product list.
- Lines 21 - 27 build a prompt as a string. This is the prompt that will be sent to the LLM for each product.
The Prompt sent to the LLM will be in the following format (text abbreviated with ellipses for clarity):
[
{ "role": "system", "content" : "Assistant is a large..."},
{ "role": "user", "content": "This product has been...\n" \
"Please very briefly summarize these reviews...\n" \
"I had it for one month and it...\n" \
"I'm reviewing the 25 variant here. The casing is sure to be..\n"
}
]- Line 29 makes the actual call to the OpenAI GPT 3.5 Turbo deployment created in Azure, and waits for a response from the LLM.
- Line 37 appends the review summary to the output array, along with the original product id and product title.
Create a new Spark DataFrame
After all review summaries are generated, the array is transformed into a Spark DataFrame that can be further analyzed or stored.

Write the Results to a new Delta Table
Finally, we'll write the results to a new Delta Table.

Now we can use Spark SQL (or other methods) to read data from the Delta table and use the summaries in other solutions, such as Power BI reports!
Code Available
The Jupyter notebook used in this post is available on GitHub using this link.




