Azure AI Services includes a service to analyze text content, and assign a sentiment analysis rating. This service is exposed via high level SDKs including Java, JavaScript, C# and Python. It's also available via its underlying REST APIs.
From a Fabric Jupyter Notebook, we can also access Azure AI Sentiment analysis by using the pre-installed Synapse ML libraries. In this post we'll use this Synapse ML library to apply sentiment analysis to each row of a Spark DataFrame according to the sentiment of user review content.
Video Tutorial Available
The balance of this tutorial-orientated post is available in video format on YouTube using the following embedded video. The rest of the text walk-through continues after the embedded video.
Input Data
Our input data is stored in a Delta Table within a Fabric Data Lake.
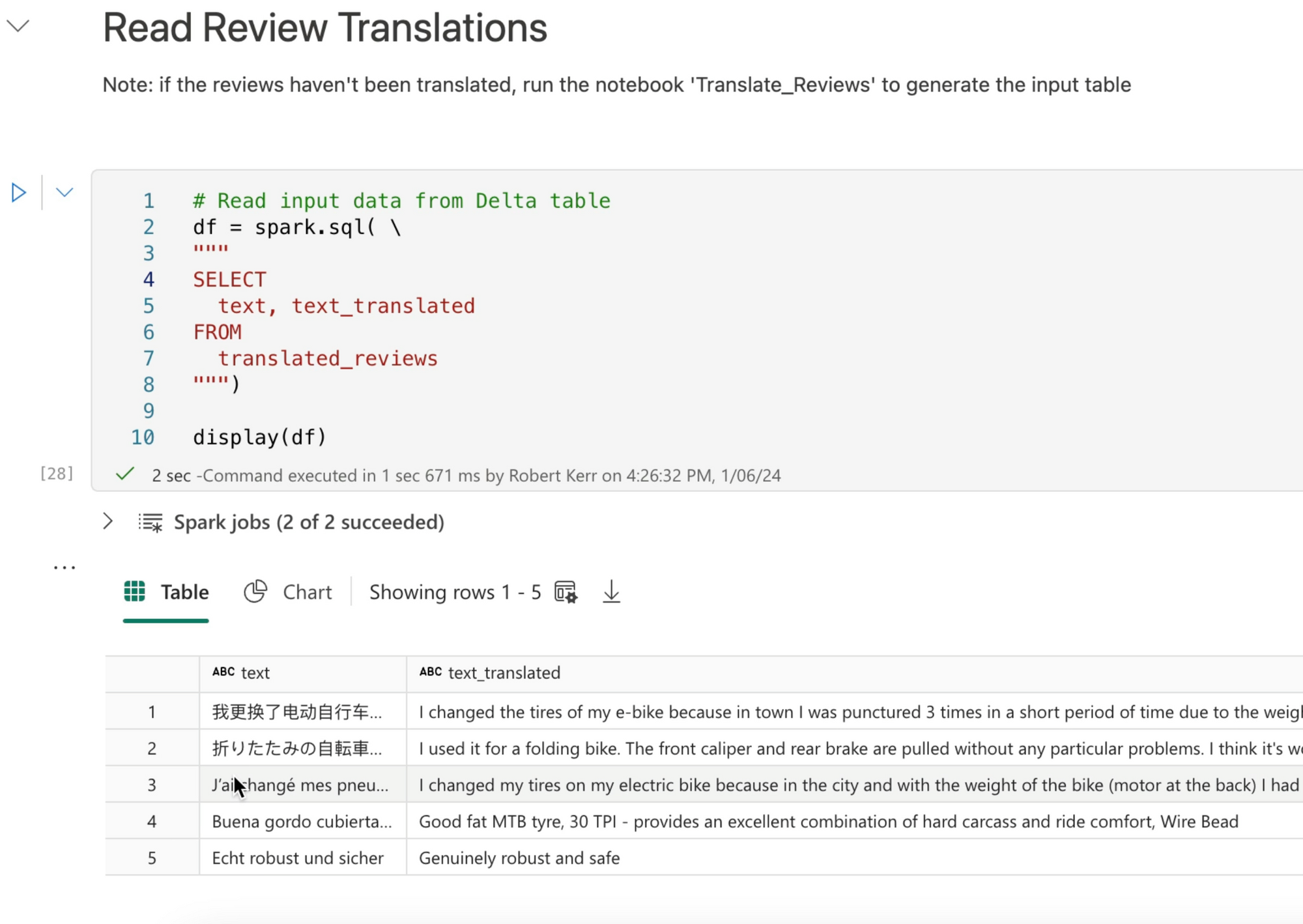
The translation of data was the output of a previous post on language translation in Microsoft Fabric notebooks.
Fetching Azure AI Key from Key Vault
The sentiment analysis transformer requires a key to use the Azure AI Service. When using secret keys in notebooks, we don't want them in the notebook source code, and as a best practice store them in Azure Key Vault.
Microsoft provides the PyTridentTokenLibrary to securely access Key Vault secrets from Jupyter Notebooks.

When this cell completes, we have the Azure AI access key stored in the access_token session variable.
Create and Use a Synapse Transformer
To process the input DataFrame with Azure AI Services, we create a Synapse TextTransformer, and configure it according to our input and output requirements:
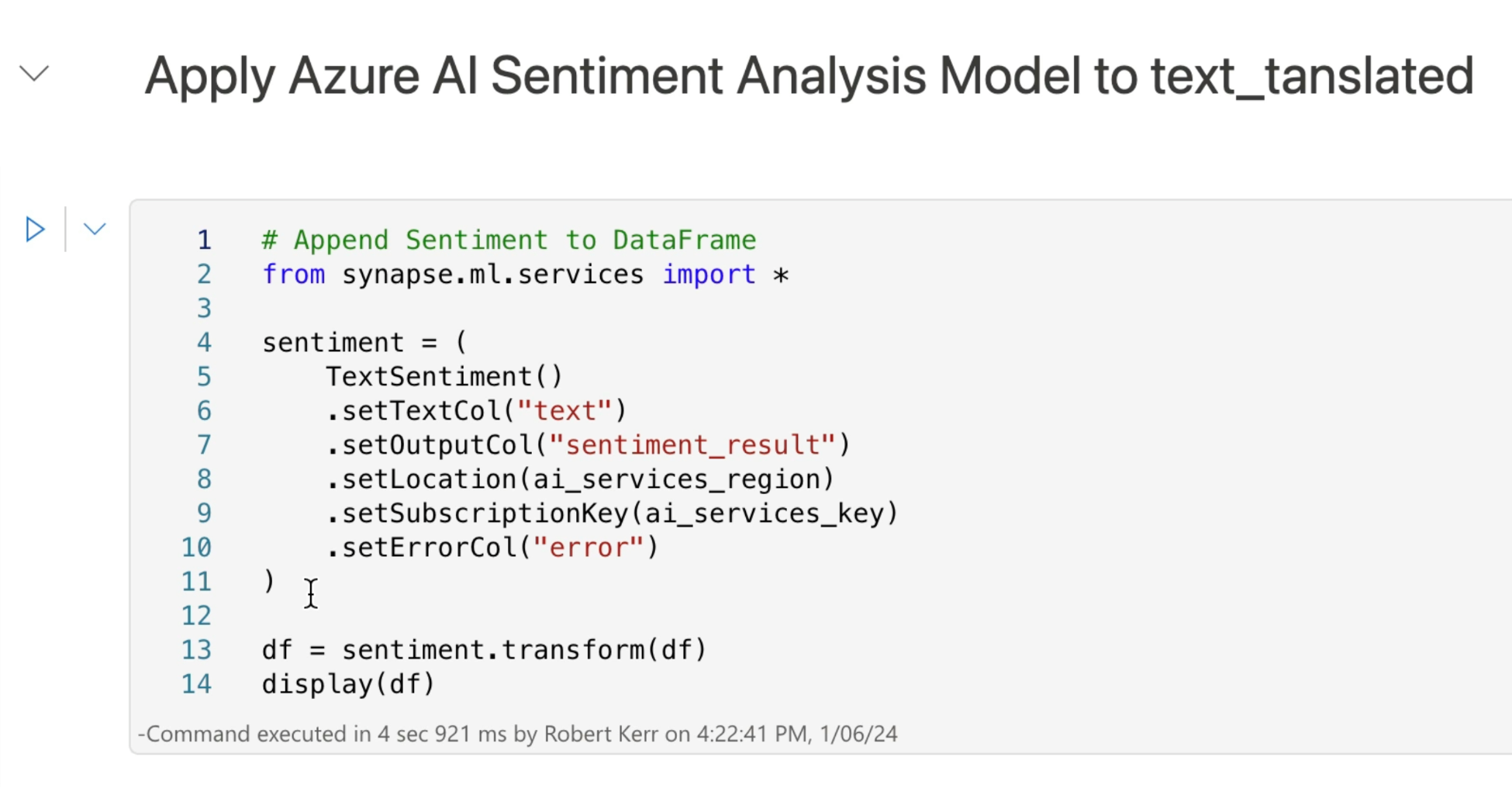
- One line 6 we specify that the
textcolumn will be the source of data for sentiment analysis. - On line 7 we specify that the sentiment result will be added to the DataFrame in a column called
sentiment_result. - Lines 8 and 9 specify the region where we created our Azure AI service, and the key for that service.
- Line 10 specifies that if errors are encountered when analyzing text for sentiment, those errors should be added to a new column
error.
Line 13 runs the transformer, and provides DataFrame df as the transformer's data source.
Review Transformer Output
The output of the transformer is a Spark DataFrame with the sentiment column appended.
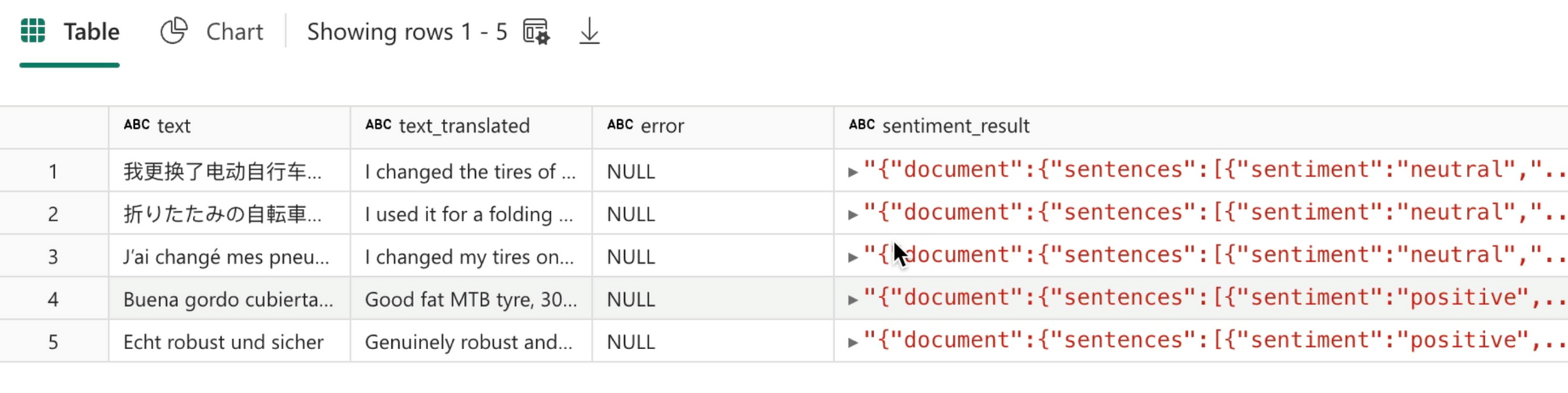
The sentiment_result column is a JSON object, that contains a wealth of information, including confidence, sentiment of sub-sections of text, and an overall sentiment evaluation.
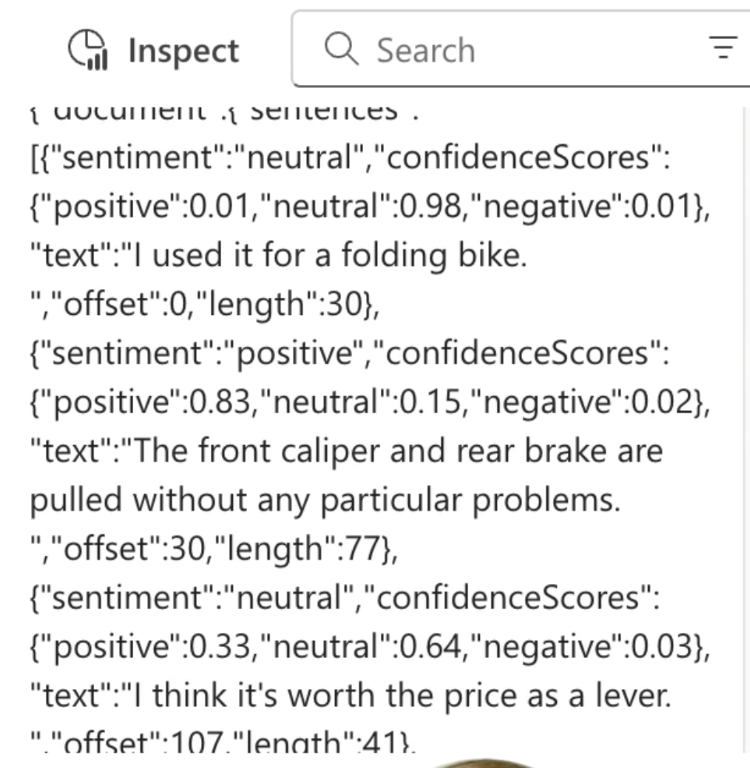
Note that the sentiment of each sentence has been calculated, as well as an overall sentiment.
Extract Sentiment
In this example, we'll simply extract the overall sentiment value and add it to a DataFrame along with the original and translated text.
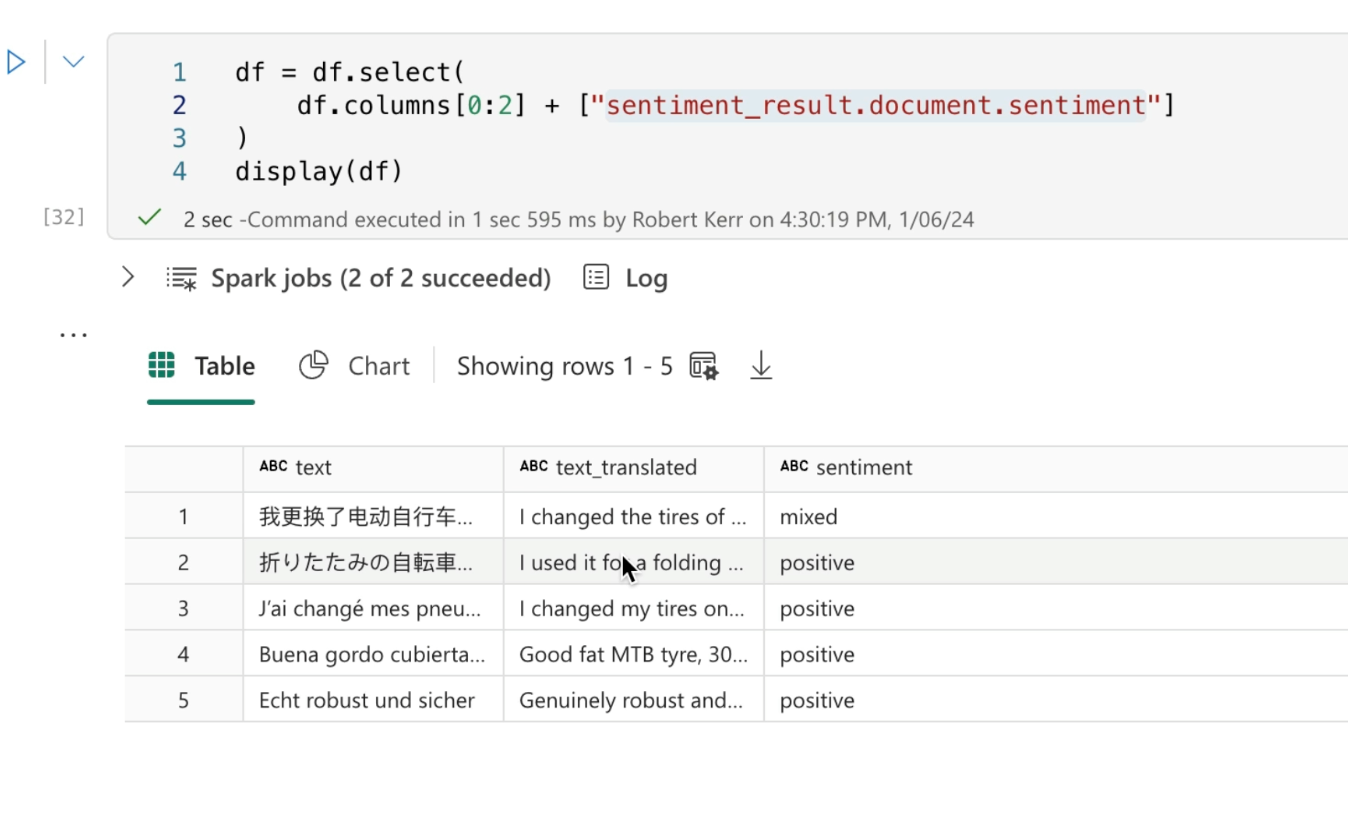
Save Result to the Data Lake
Let's save the result to the Data Lake as a Delta Table.

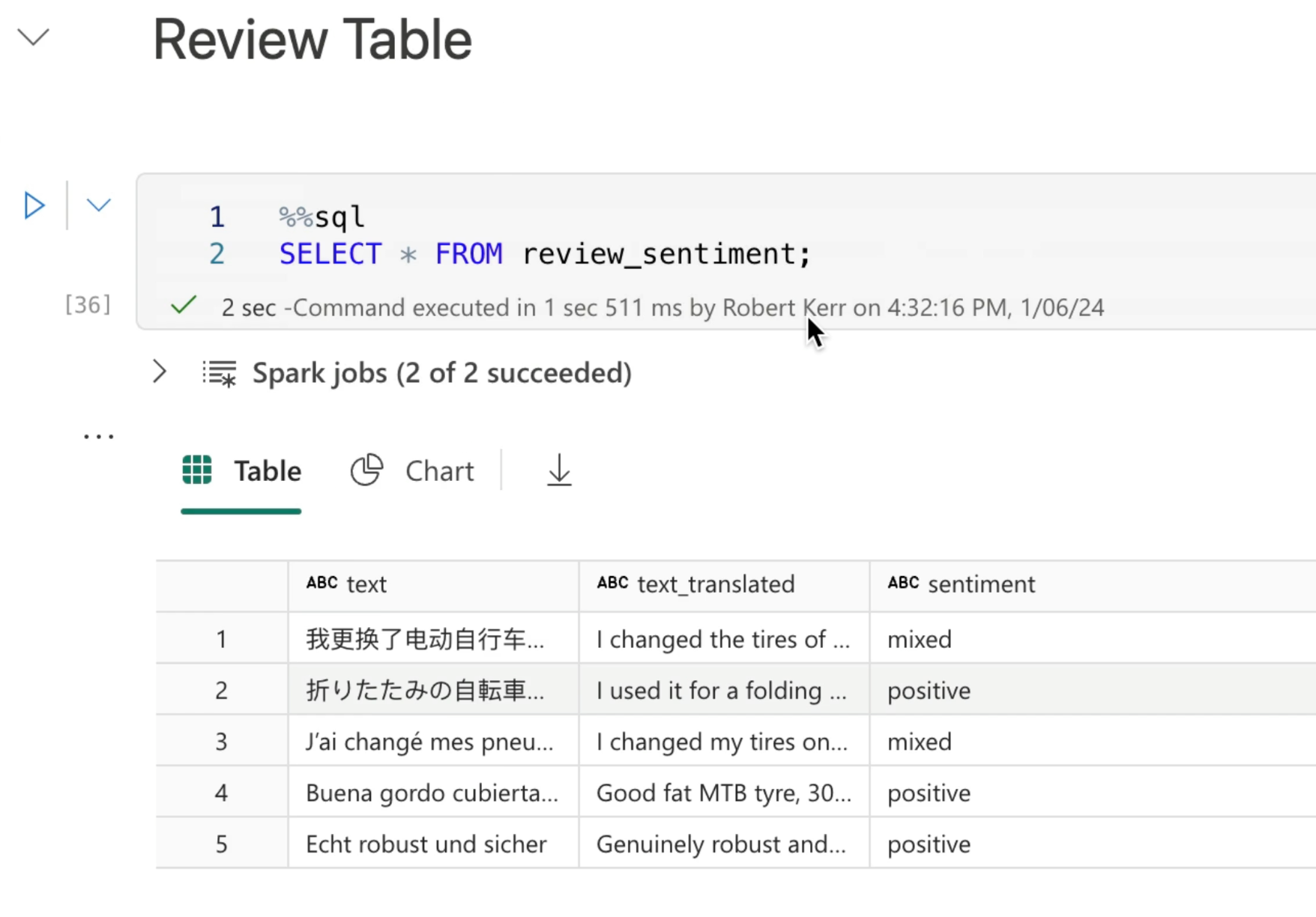
And finally, we'll query the saved output table to ensure it was correctly written to the Data Lake.
Code Available
The Jupyter notebook used in this post is available on GitHub using this link.