Python Jupyter notebooks run in a Spark Compute context that by default has Synapse ML libraries installed. For many Azure AI services – including translation – AI Models can be accessed without creating separate AI Services instances.
YouTube Video Demonstration
A detailed demonstration of this solution is available as a YouTube video. The remainder of the written post continues after the embedded video link.
Solution Architecture
In this post we'll use the integrated Synapse ML services to process a Spark DataFrame. The flow of this solution is as follows:
- Ingest a collection of JSON documents from an Amazon S3 bucket (via an S3 shortcut created in Microsoft OneLake)
- Call the Azure AI Translator Service via the Synapse ML Fabric SDK. In this simple example, we'll use Synapse/Azure AI to translate a user comment column in a DataFrame, appending a new column with the English translation.
- Save a DataFrame with the original and translated review text to a Delta table in the Fabric Data Lake.
Amazon S3 Input Data
In this solution our input data will be JSON documents stored in an Amazon S3 bucket.
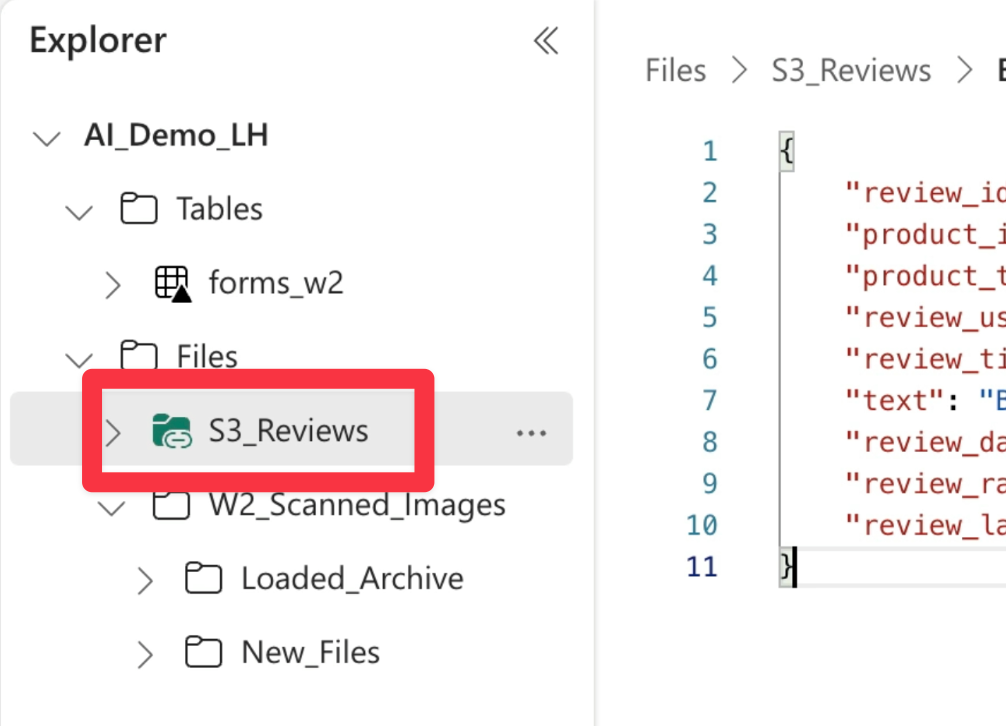
OneLake Link
In the Fabric Data Lake, we can see that the S3 bucket is configured as a link within OneLake, by the presence of the link icon next to the folder in the object browser.
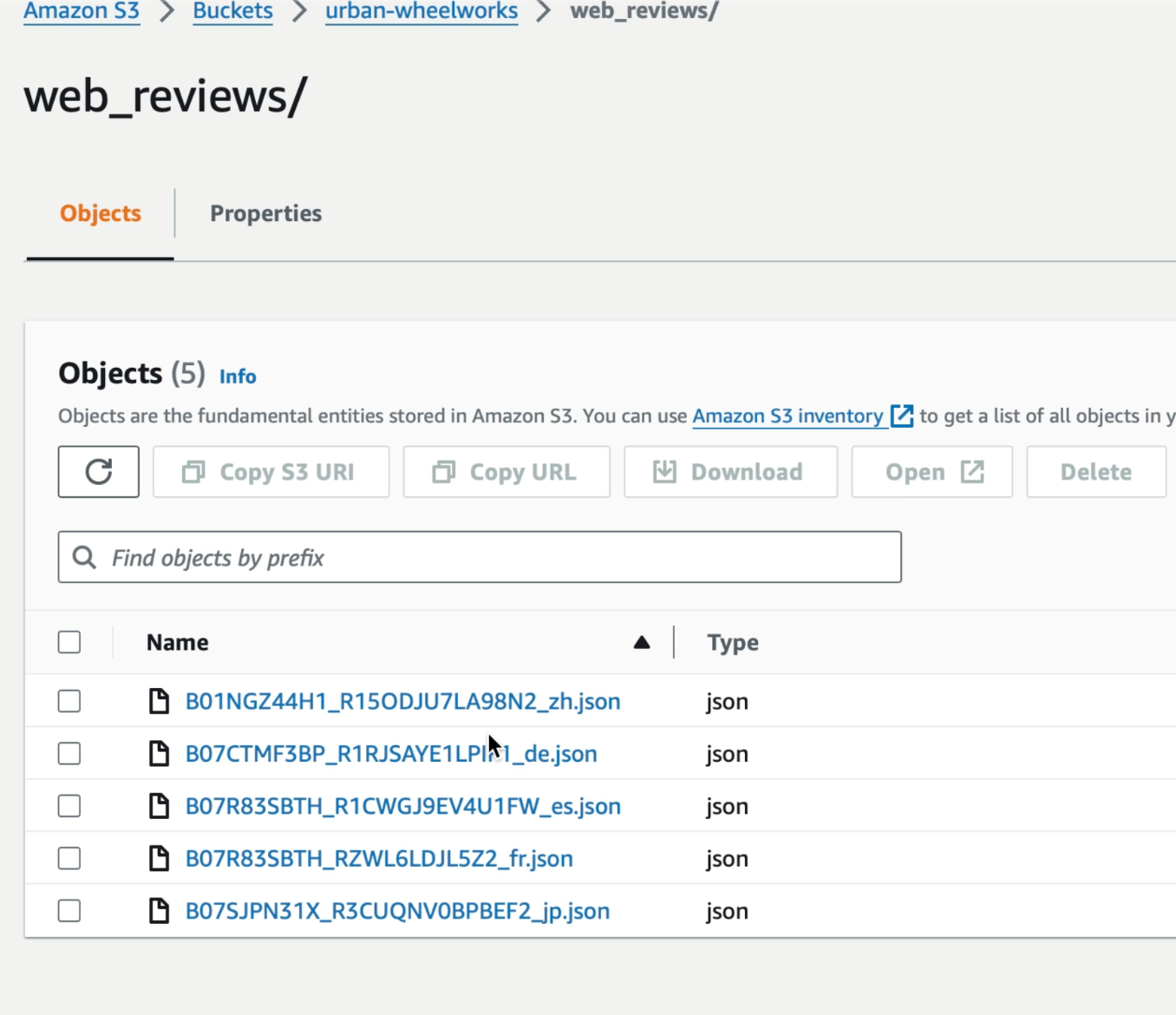
Files in the S3 Bucket
If we look at the folder in the AWS console, we can see the review files as they sit in the S3 bucket.
JSON Document Structure
Each document has the same structure and contains user-written reviews in a variety of languages (Spanish, German, French, Japanese and Chinese).

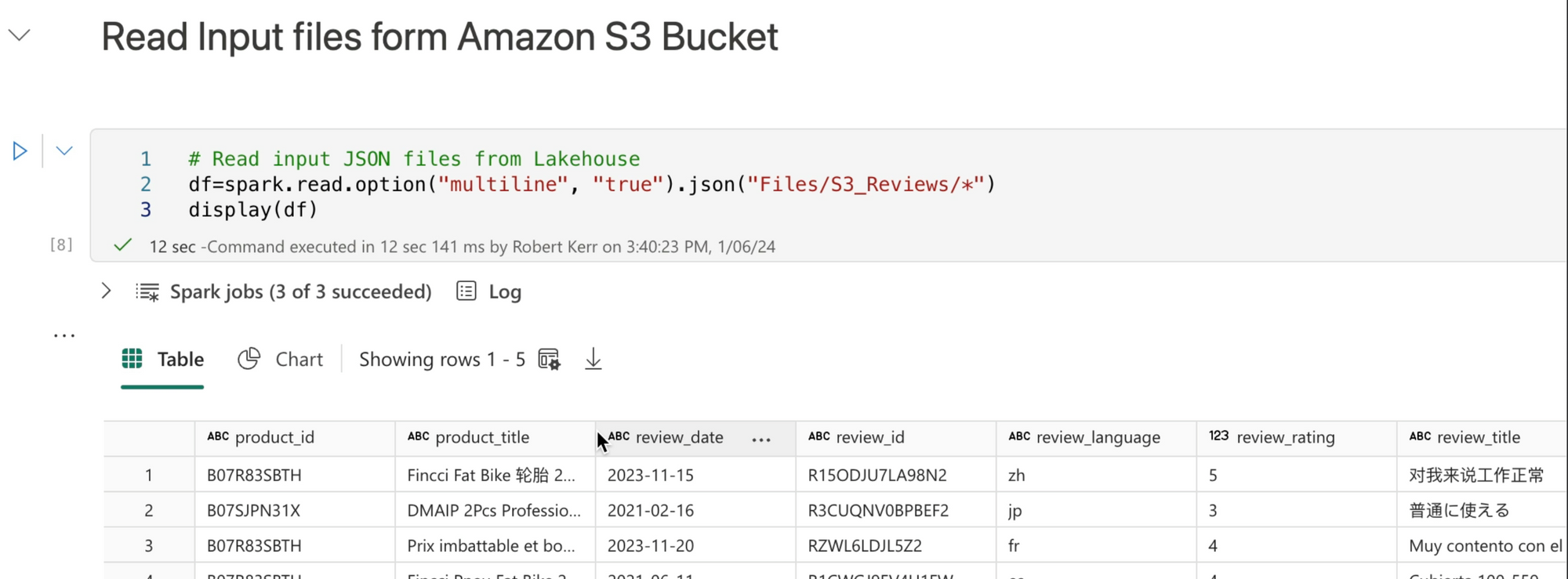
Read the Input Data from S3
Now that we've seen what our source data looks like, it's time to read the data. When calling the Spark APIs to read files from the Data Lake, there's no difference in syntax when the OneLake files are externally linked.
Call Azure AI to Translate Text
Now that we have the text to translate loaded into a Spark DataFrame, we can create a transformer to process the DataFrame through the Azure AI Translation service.

To gain access to the Synapse transformers, we'll import all classes from the synapse.ml.services package at line 2.
At line 5, we create a Synapse transformer. The transformer is configured as follows in lines 6-8:
- The input column is set to "text" at line 6
- The desired target translation language is set to English at line 7
- The output column (English translation) is set to "translation" at line 8
At Line 11 we invoke the transformer, providing DataFrame df as the source data for translation.
Review the Translations
Next let's review the translations. We can see that we have translated text for each input row in the DataFrame.
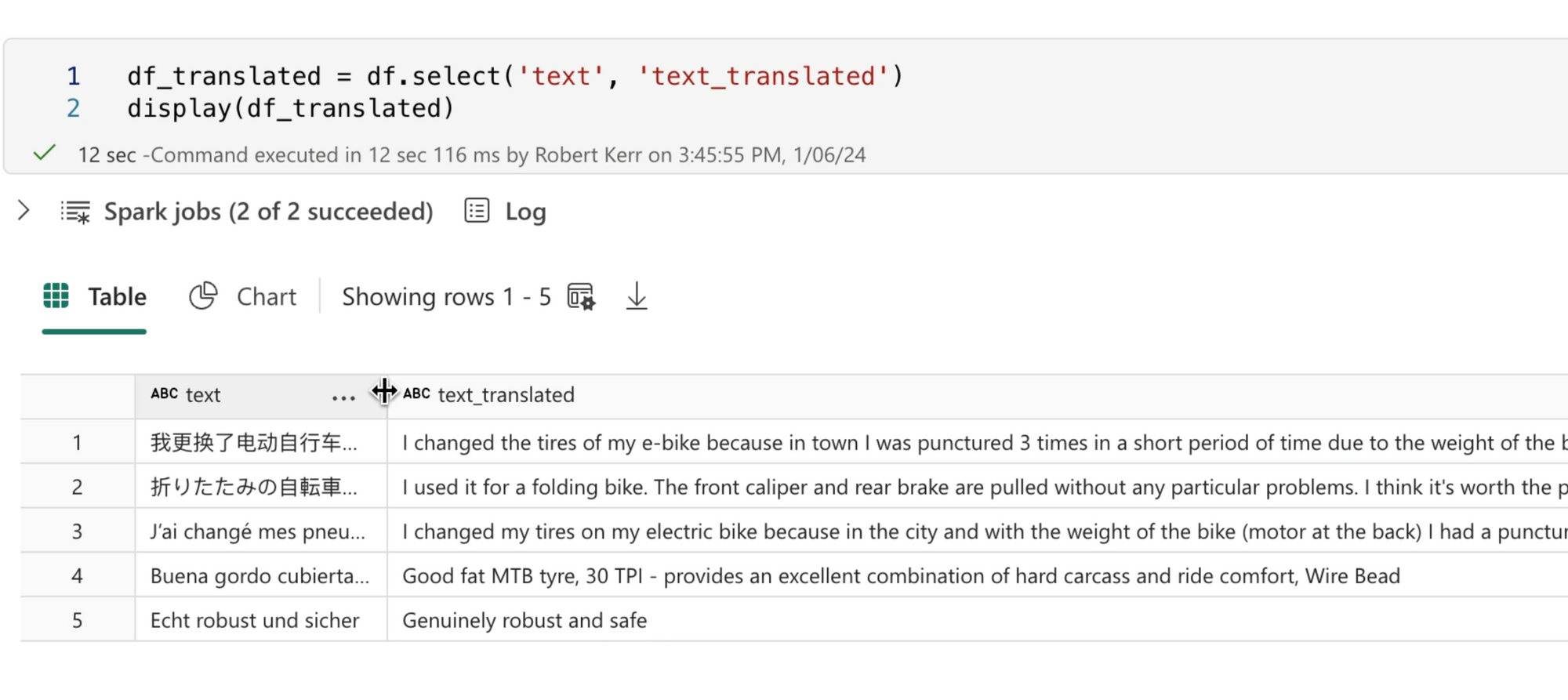
Save Output a Delta Table
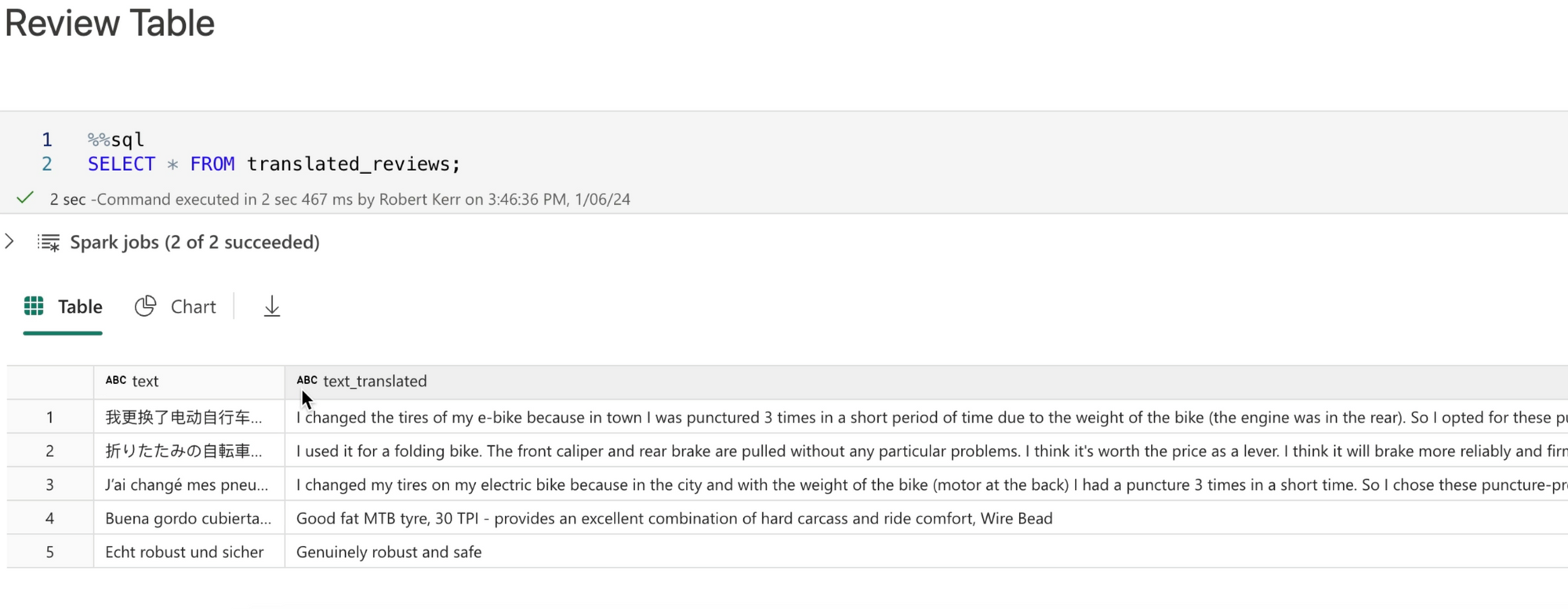
Finally, let's save the Spark DataFrame with the input and outuput text to a Delta table in the DataLake.

Finally, we use Spark SQL to read the table back into a DataFrame to ensure the data was saved correctly.
Code Available
The Jupyter notebook used in this post is available on GitHub using this link.