


About the Azure Model Catalog
When using pre-trained foundation models in our applications, we have several ways to incorporate them into our solutions, including:
- Using a pre-trained model-as-a-service on a "price per token" basis, such as OpenAI GPT4.
- Downloading models from repositories like Hugging Face and provisioning our own server compute (e.g. a VM that runs a large language model).
- Deploying a model and endpoint from a cloud provider Model Catalog, such as Azure, AWS or Google Cloud
In this post I'll walk through the process of deploying a foundation model from the Microsoft Azure Machine Learning Model Catalog, creating a REST endpoint, and then calling the REST endpoint from an external application.
Creating an Azure Machine Learning Workspace
To use the Azure Machine Learning Model Catalog, we'll first need an Azure Machine Learning workspace. To create a workspace, we'll add a new Resource Group, and then create an Azure Machine Learning service within the resource group.
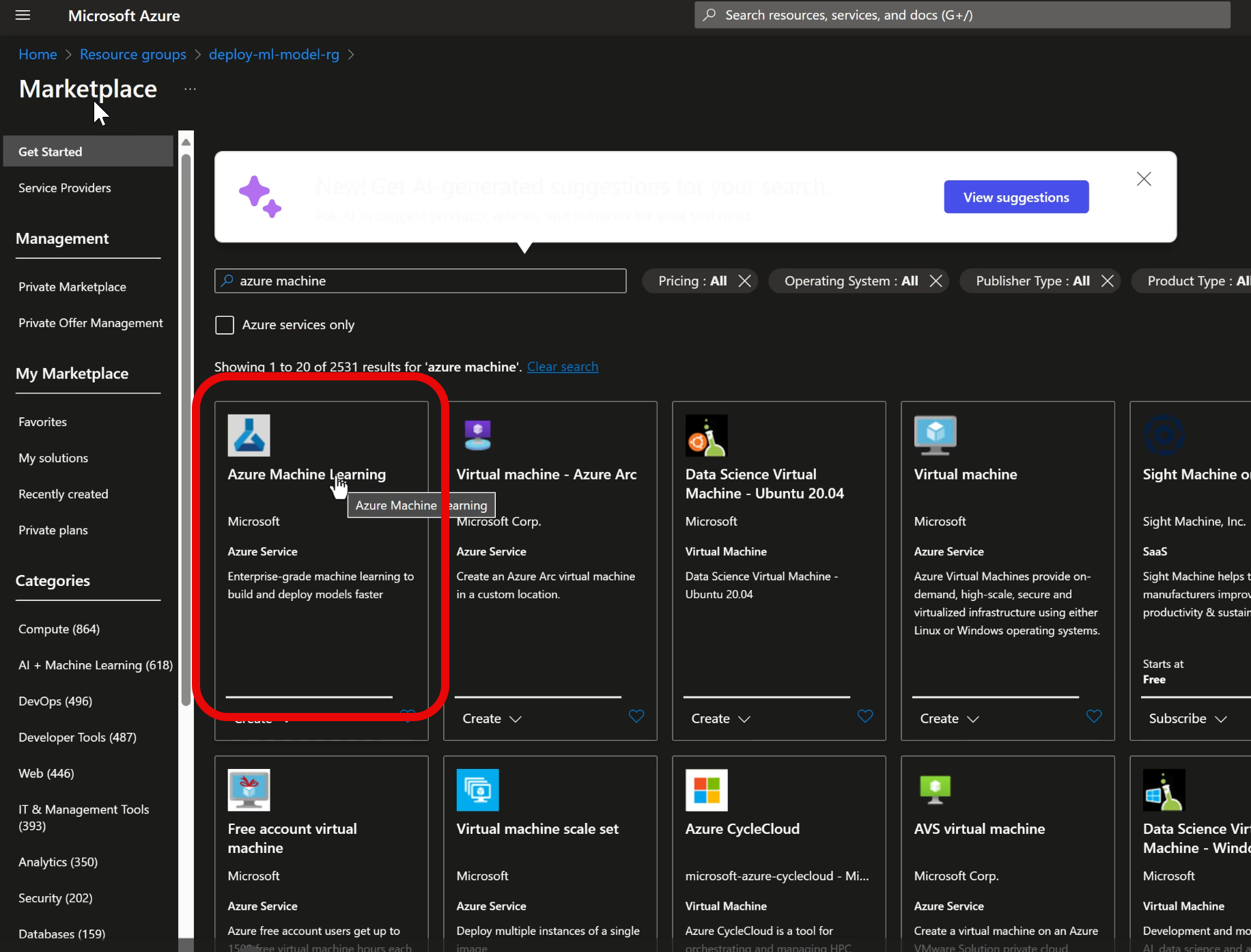
Once the Azure ML workspace is created, we launch the Azure ML Studio. We can either use the launch button from the Azure resource, or browse directly to http://ml.azure.com.
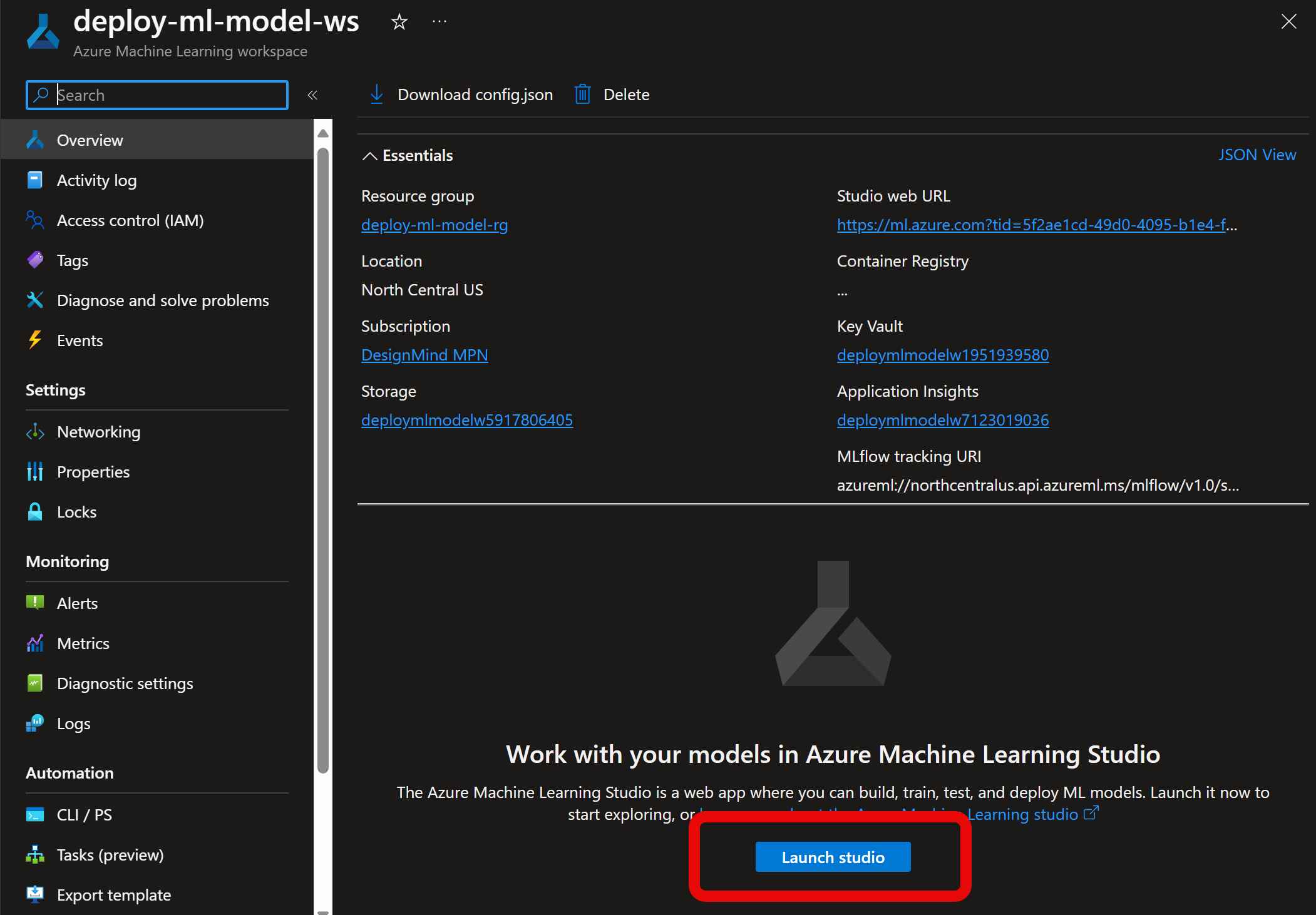
Select a Model from the Model Catalog
Once in the Azure ML Studio, we can browse the model catalog and select a model that meets our needs. Each model has summary information, and links to the originator of the model we can follow to learn more about each one.
Deploying a Model
Once we've found the model we want to use, we can deploy the model right from Azure ML Studio.
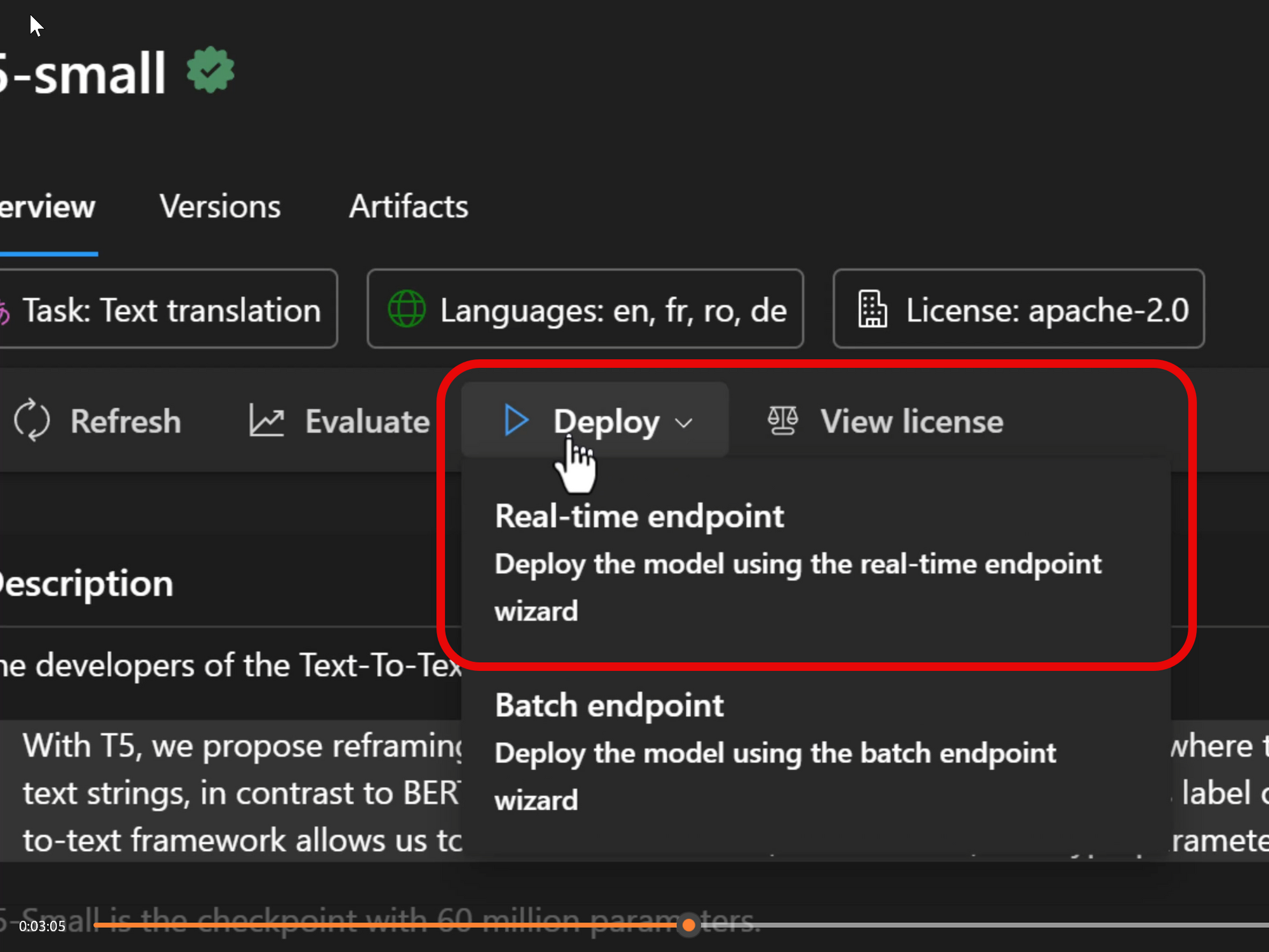
Deploying a model from the Model Catalog automatically provisions two resources within our Azure Resource Group:
- A compute instance to host the model within our Azure account.
- A compute instance to host a REST endpoint that allows external applications to send queries to the model we deployed.
Consuming the Endpoint
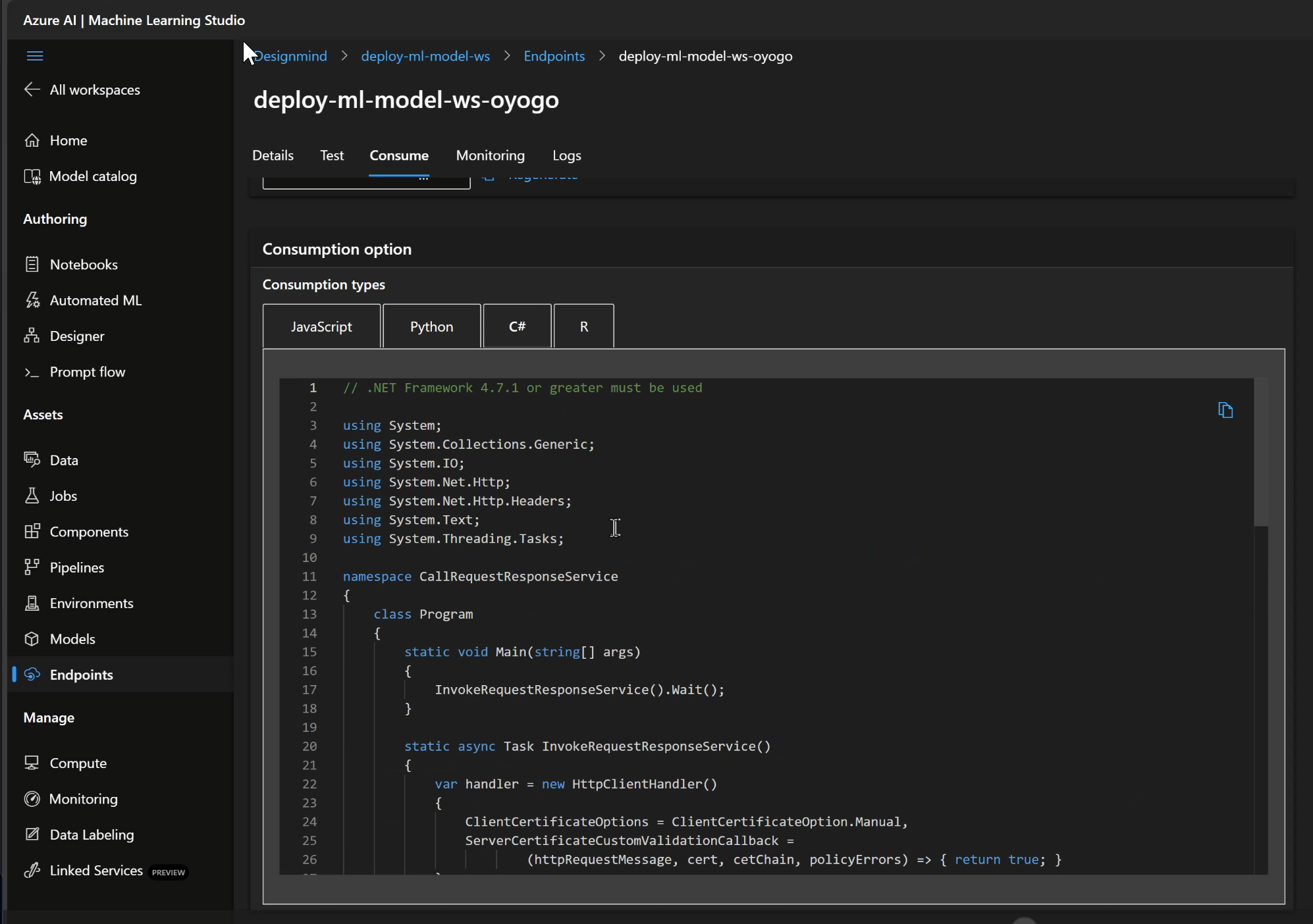
When the model and endpoint are provisioned and on-line, we can review the deployment. Calling the endpoint requires the following inputs:
- The REST URL for the deployed endpoint
- A bearer token to add to the REST request header
- The name of the model to send a request to (there can be more than one model per endpoint)
Within the Azure ML Studio, sample code is provided in JavaScript, Python, C# and R to get us started.
Calling the Endpoint
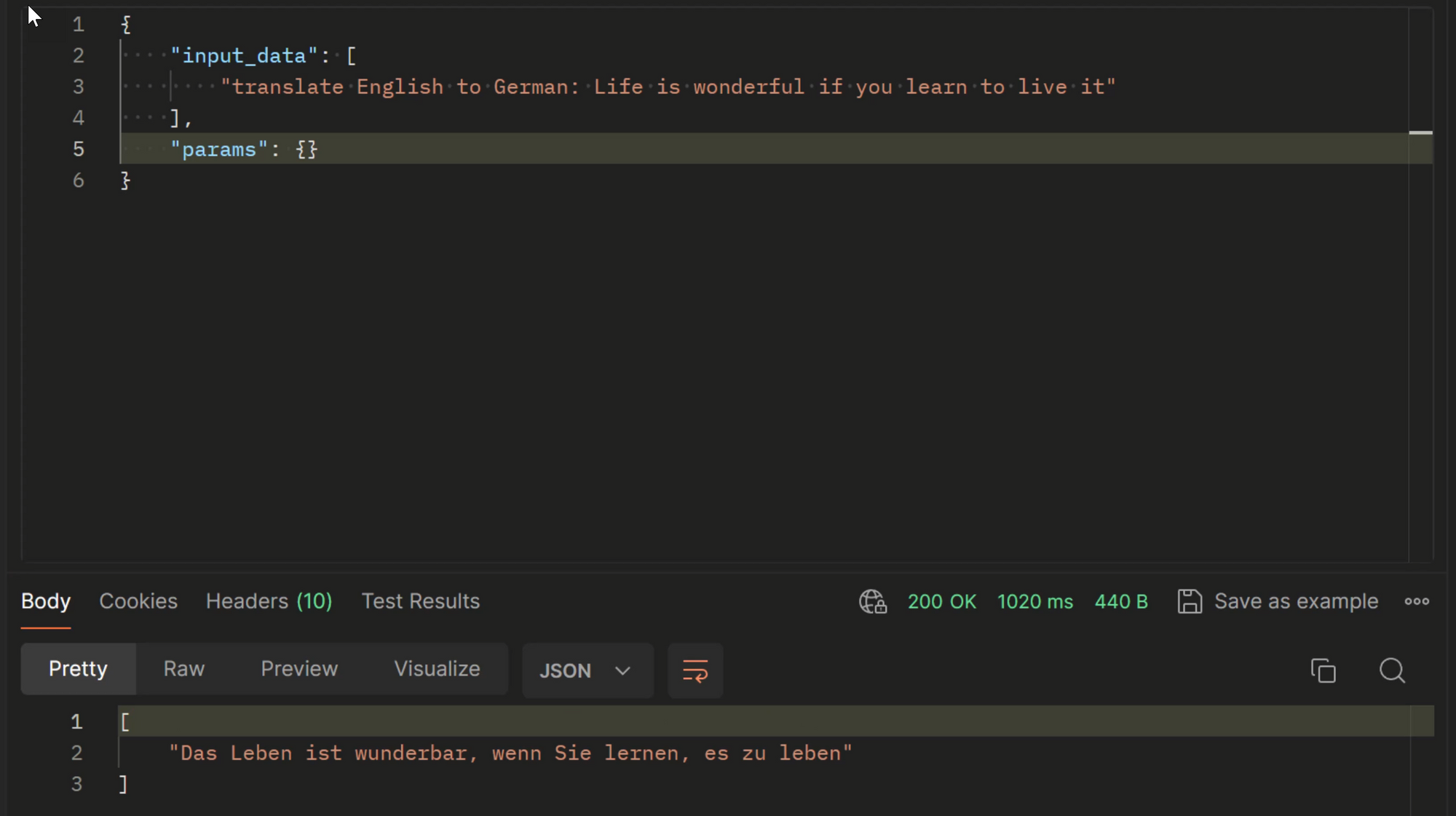
We can now send prompts to the deployed model, and have responses returned to our application in JSON format.
Below is an example of calling the model we deployed using Postman:
Summary
There's a vast array of foundation models available to use for generative AI solutions, and the number and quality is growing by the day. Often the challenge is how to provision and host models so they're accessible by applications that can make use of their capabilities. Model Catalogs in cloud platforms like Azure make this process convenient and relatively easy to manage.


