


Ingesting Snowflake data into Microsoft Fabric is supported as a 1st-party integration by Microsoft, primarily in two ways:
- As batch processes that can be scheduled, for example with Fabric Data Pipelines.
- In near real-time, using change data capture-backed Mirroring
In this post, we take a look at setting up Mirroring to replicate data from Snowflake into a Fabric Data Warehouse.
Mirroring Advantages
The primary advantages of the mirroring approach:
- Data is mirrored nearly in real-time, making Mirroring an ideal solution for solutions where up-to-the-minute data is needed to enable decisions.
- Relatively easy to set-up. Since Mirroring simply copies entire Snowflake tables (or optionally all tables in a Snowflake database), the setup is mostly point-and-click.
Mirroring Disadvantages
There are some scenarios where mirroring may not be the best data integration choice:
- Mirroring requires Snowflake compute CPU cycles to run and could lead to a higher Snowflake compute cost. This is expected, since the processes that detect, query and forward data from Snowflake require compute cycles.
- Mirroring isn't designed to incorporate transformation as would be part of an ETL/ELT pattern. Data is mirrored as-is, so if data transformation during loading is desired, a data pipeline may be a better approach.
Video Walk Through
I highly encourage watching the companion YouTube Video for this post. In 6 minutes, it covers the entire configuration and test of mirroring. However, a text version follows the embedded video link.
Enabling The Mirroring Feature
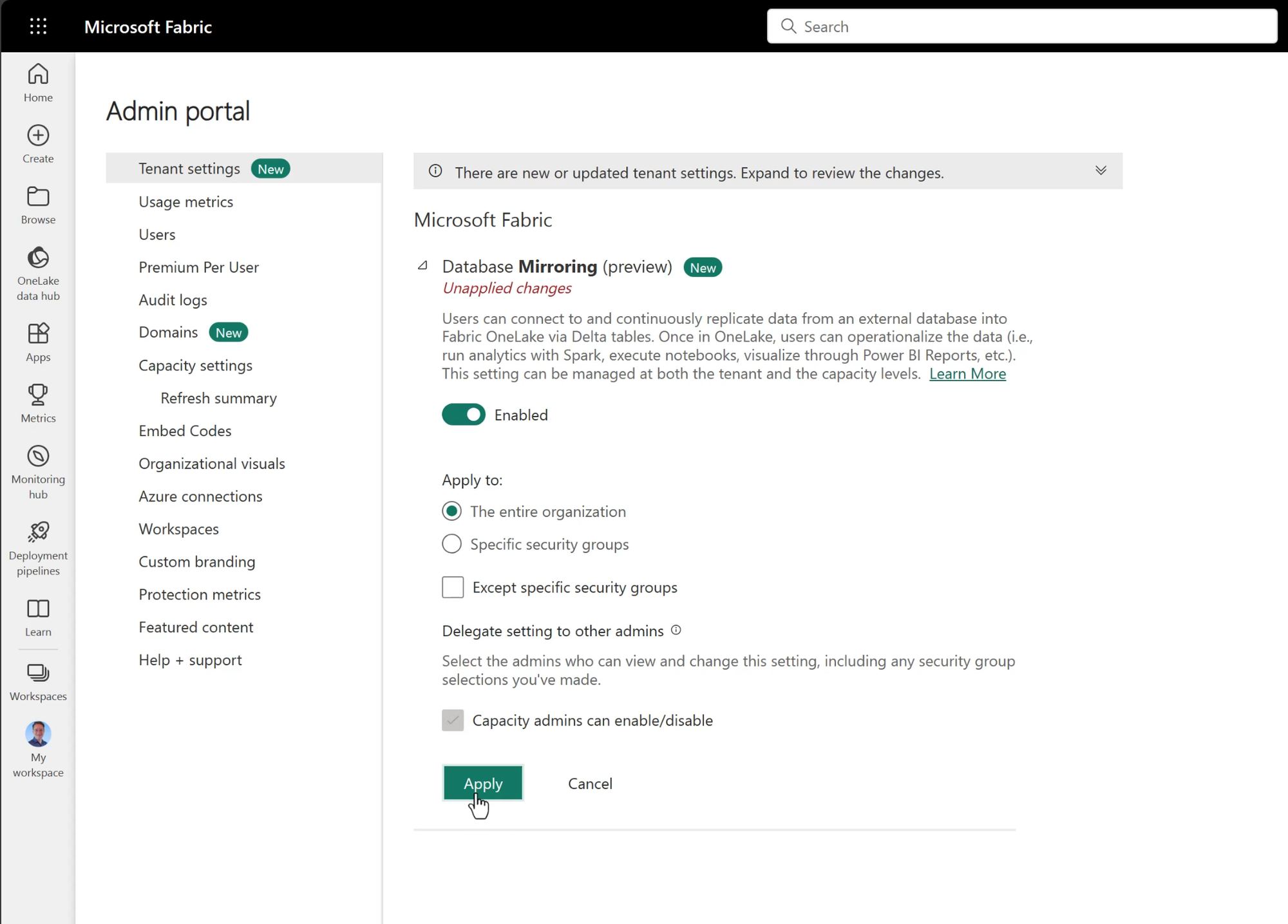
Before creating a Database Mirror, the Fabric Mirror feature needs to be enabled in the Fabric Admin Console.
Create a Mirror
With the Mirroring feature enabled in the Admin console, we can create a new mirror, using the icons added to the Data Warehouse workload landing page.
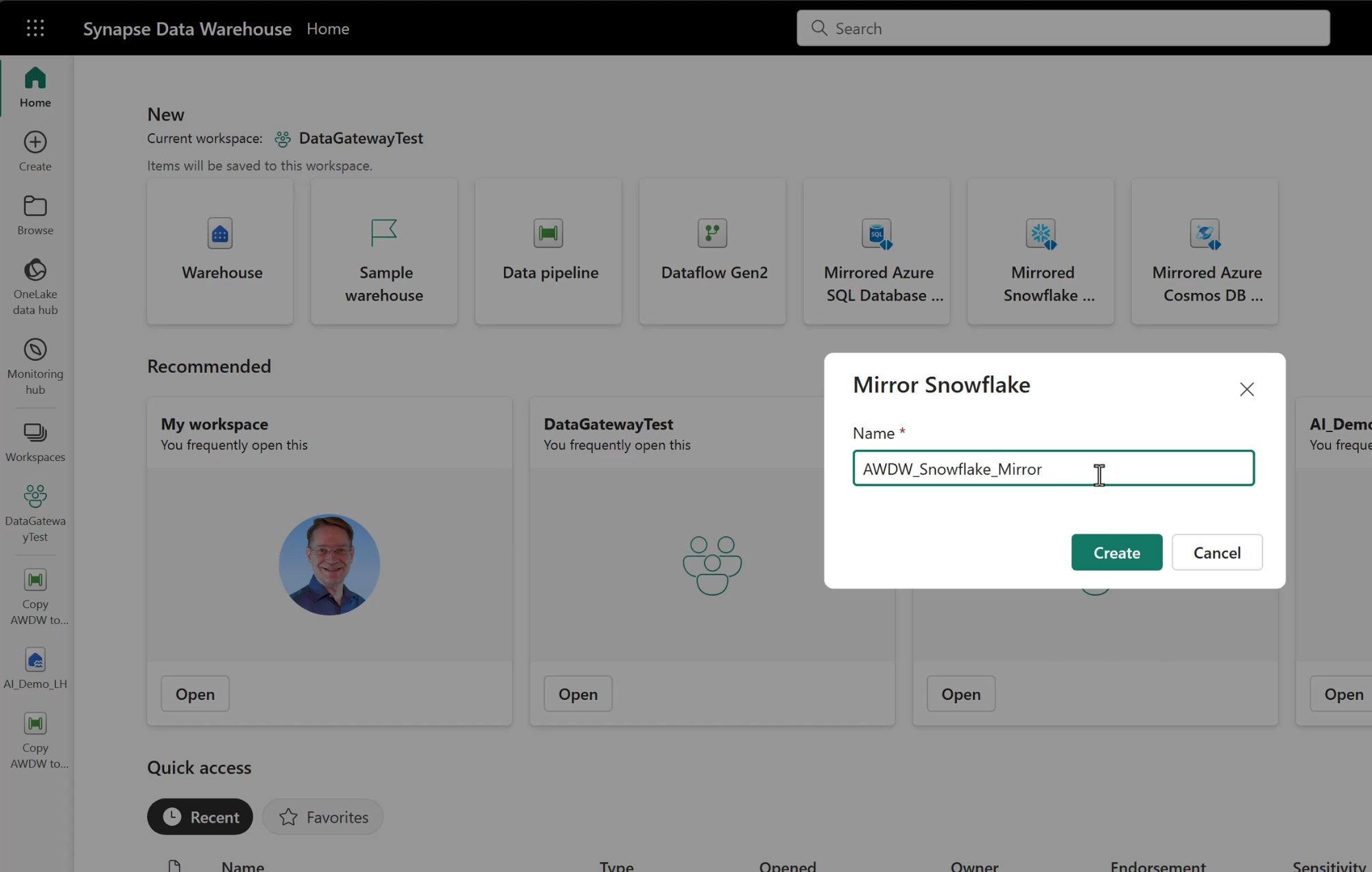
Configure the Snowflake Connection
To replicate data from Snowflake, Fabric needs to use a connection which provides connection details and authentication.
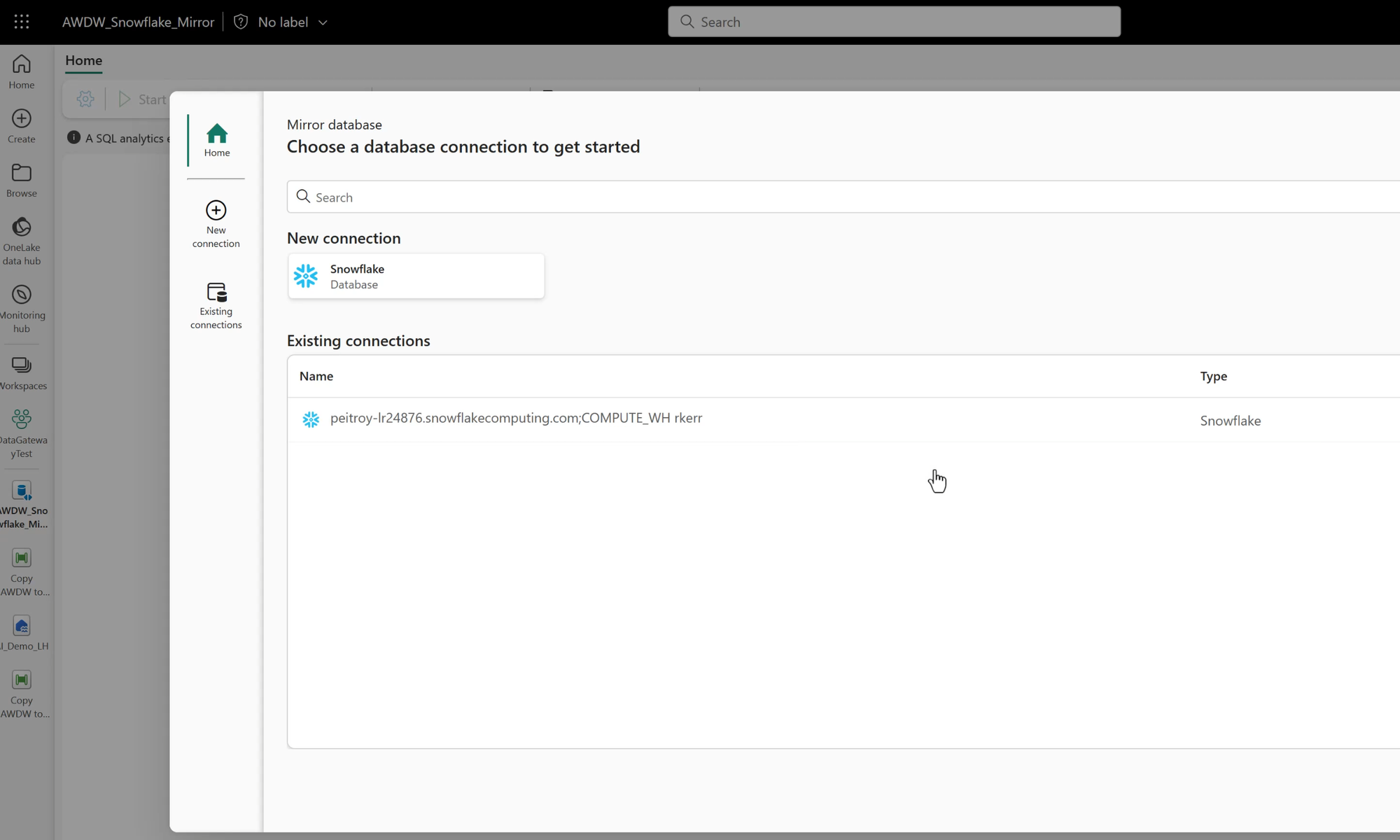
In this example, I've used a connection created in a previous video, which I'll embed here in case you'd like to see how these connections are created in Fabric:
How to create a Snowflake connection from Fabric
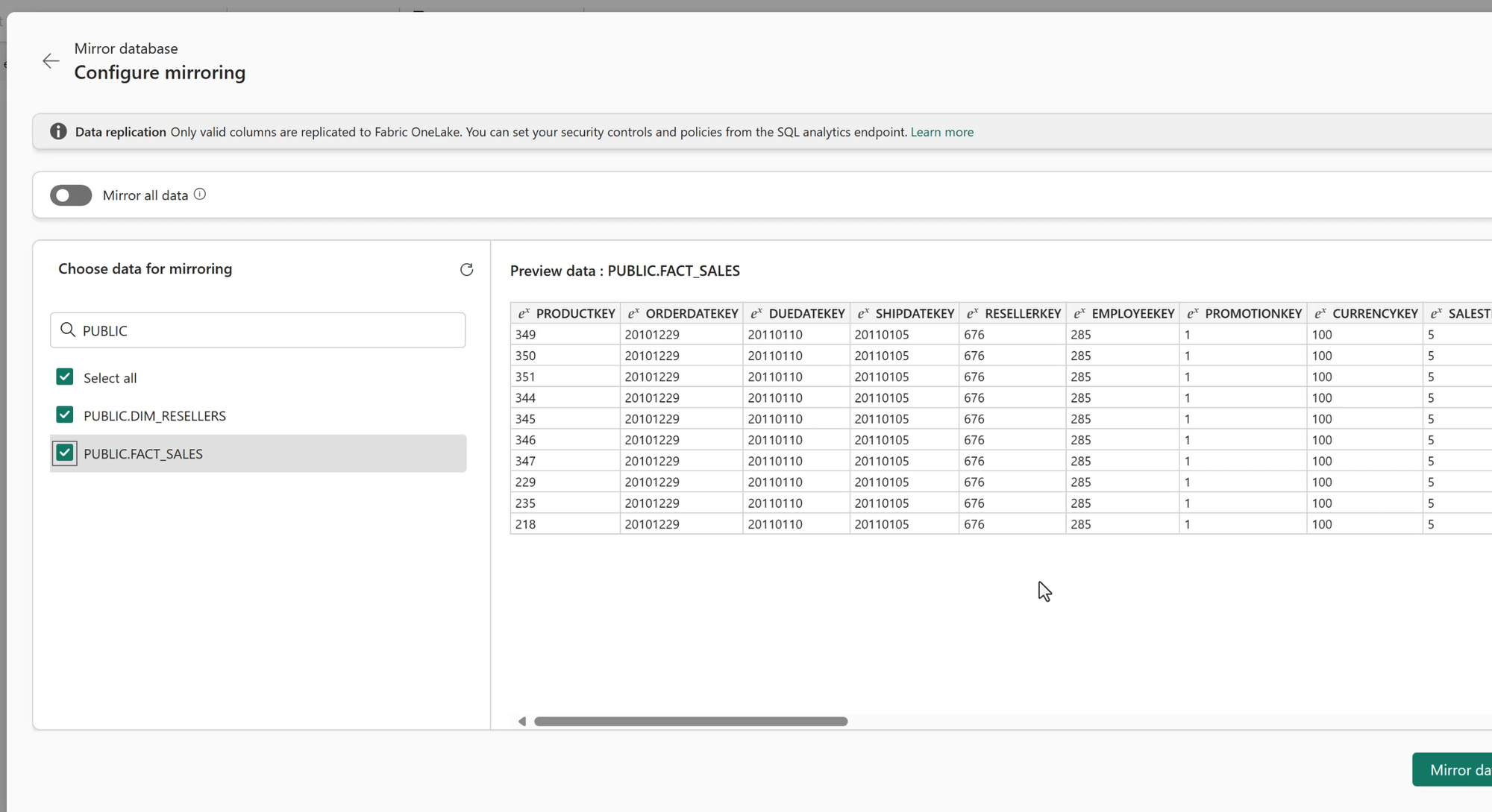
Select Source Table(s)
After selecting the Snowflake connection to use, we can select either an entire database or specific tables from Snowflake to mirror to the Fabric Data Warehouse.
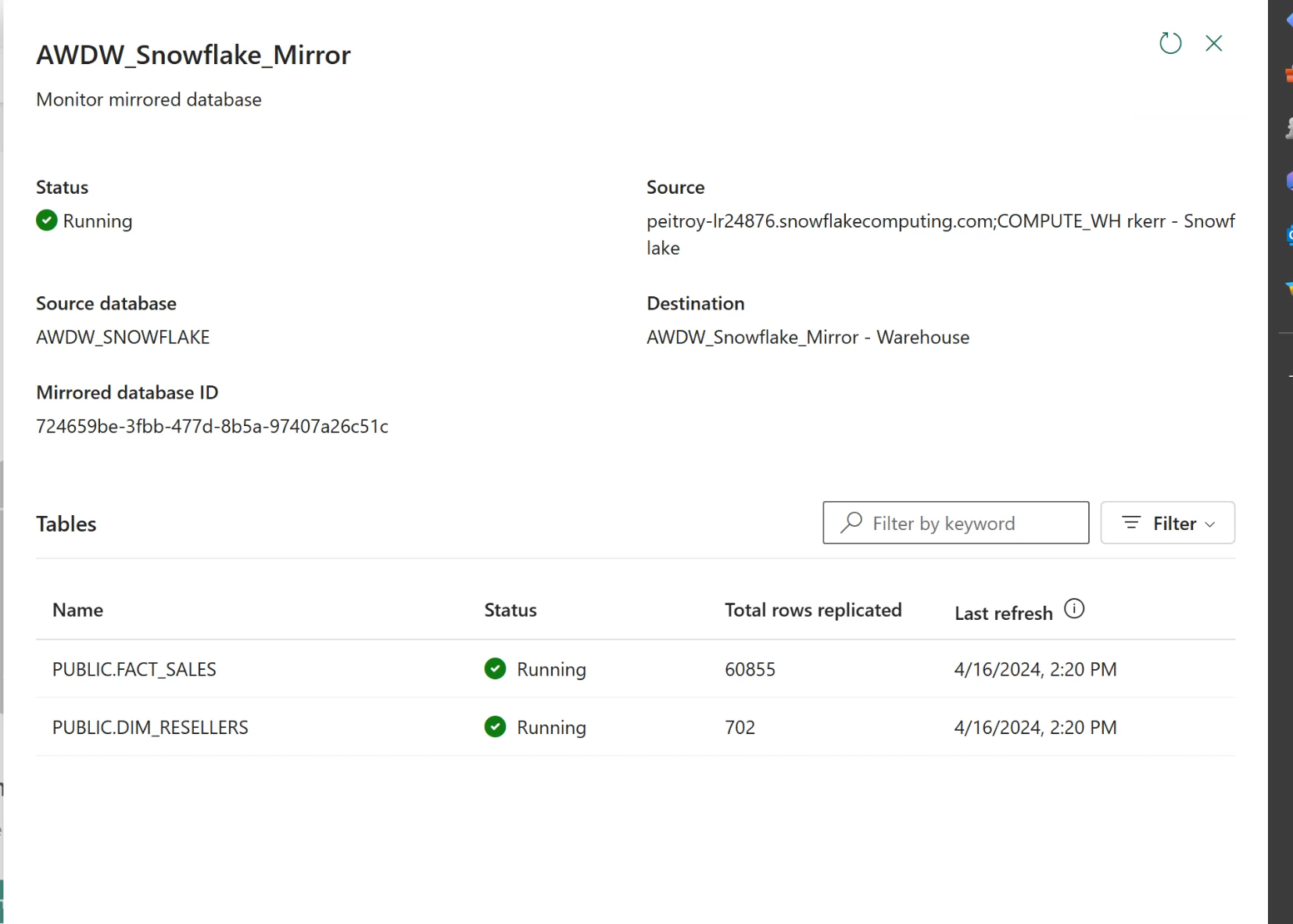
Monitor the Mirror
Once the Mirror database is created, the Mirror runs in the background. As changes are made to any of the remote Snowflake tables selected for the mirror (or all tables, if the entire database is selected), net changes are forwarded to Fabric to keep the Fabric data copy in sync.
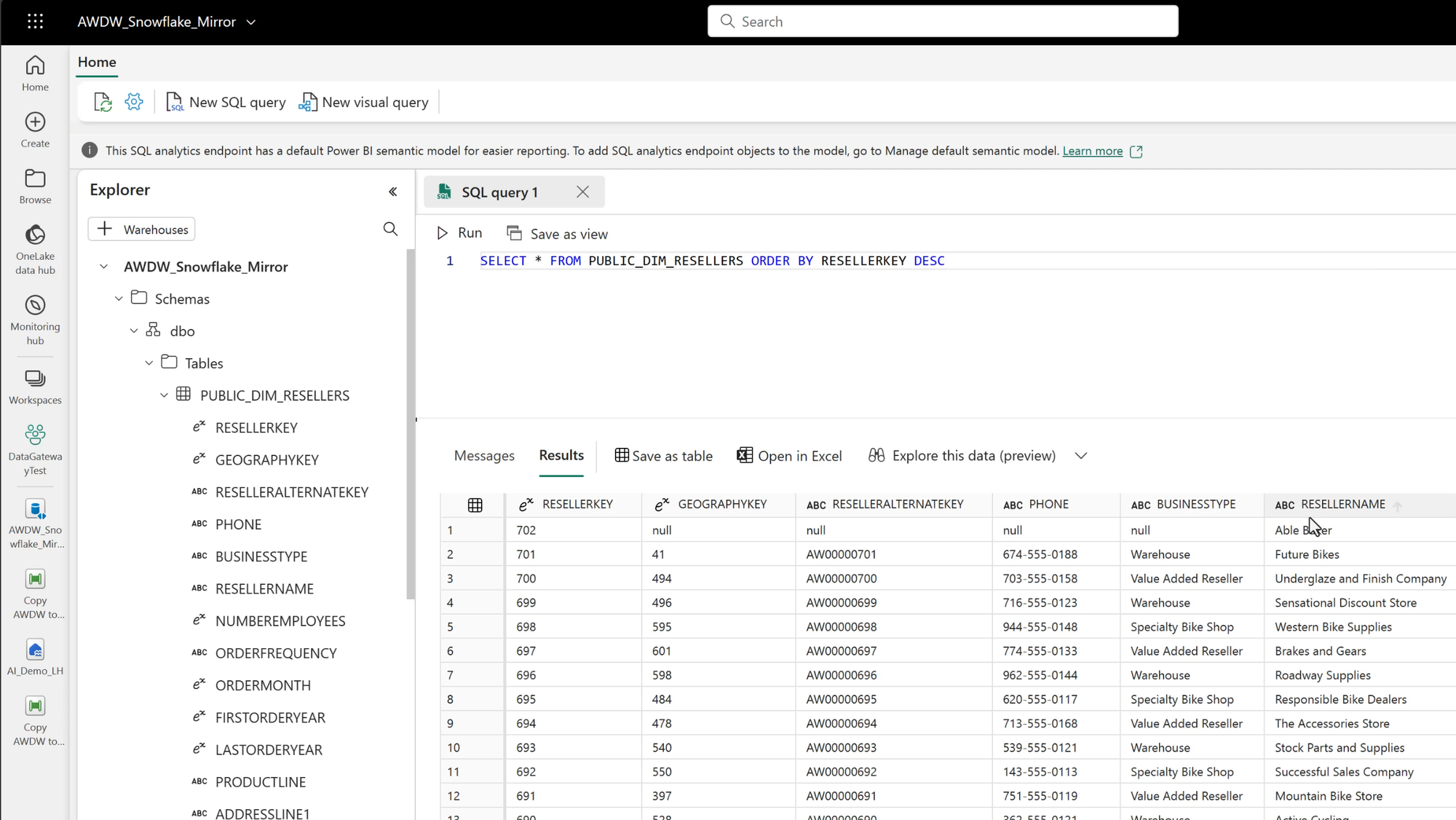
Inspect the Mirrored Tables
Once the mirrored tables are in the Fabric Data Warehouse, they can be queried as usual via the SQL Analytics Endpoint.
Mirroring Changes to Snowflake
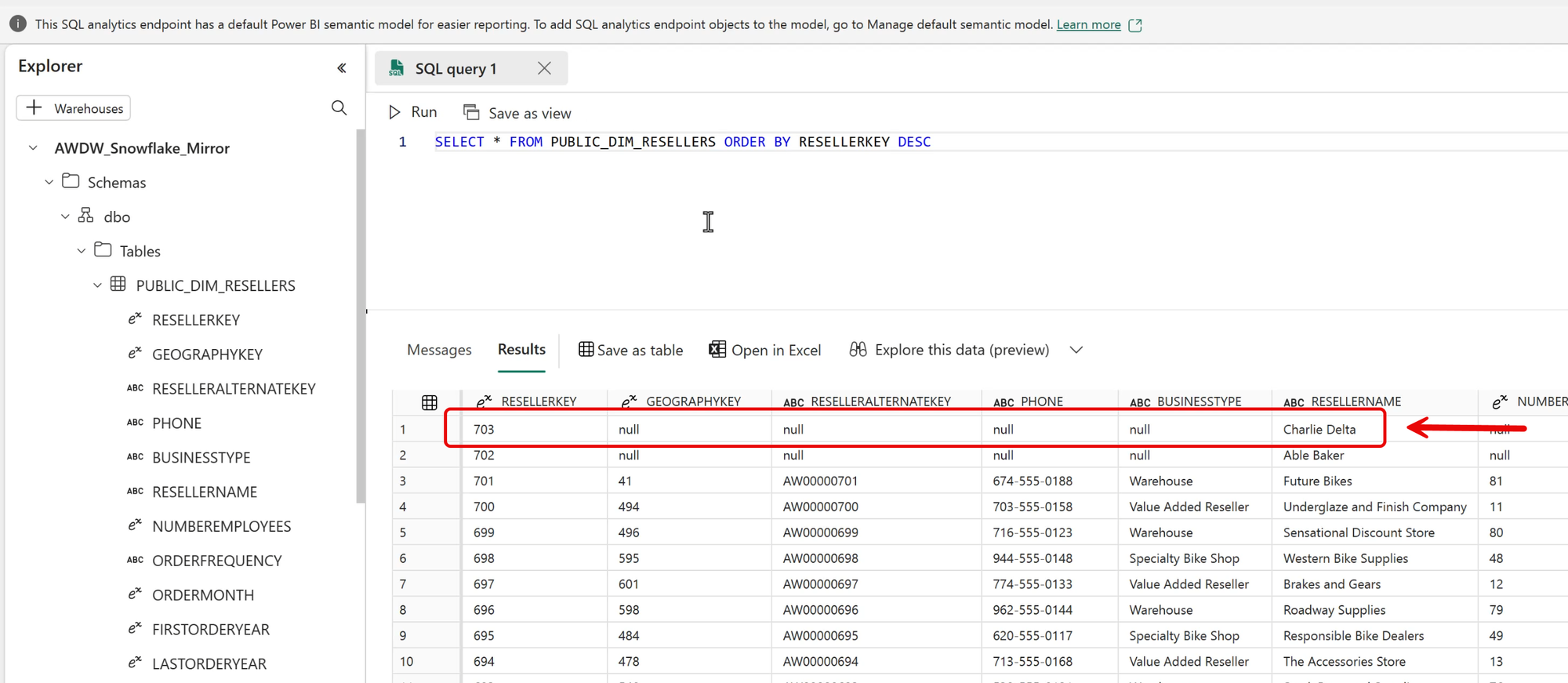
In the preceding image, the highest reseller key is 702 - "Able Baker". If we return to Snowflake and insert a new row, we'll create a new row, in this case 703 - "Charlie Delta".
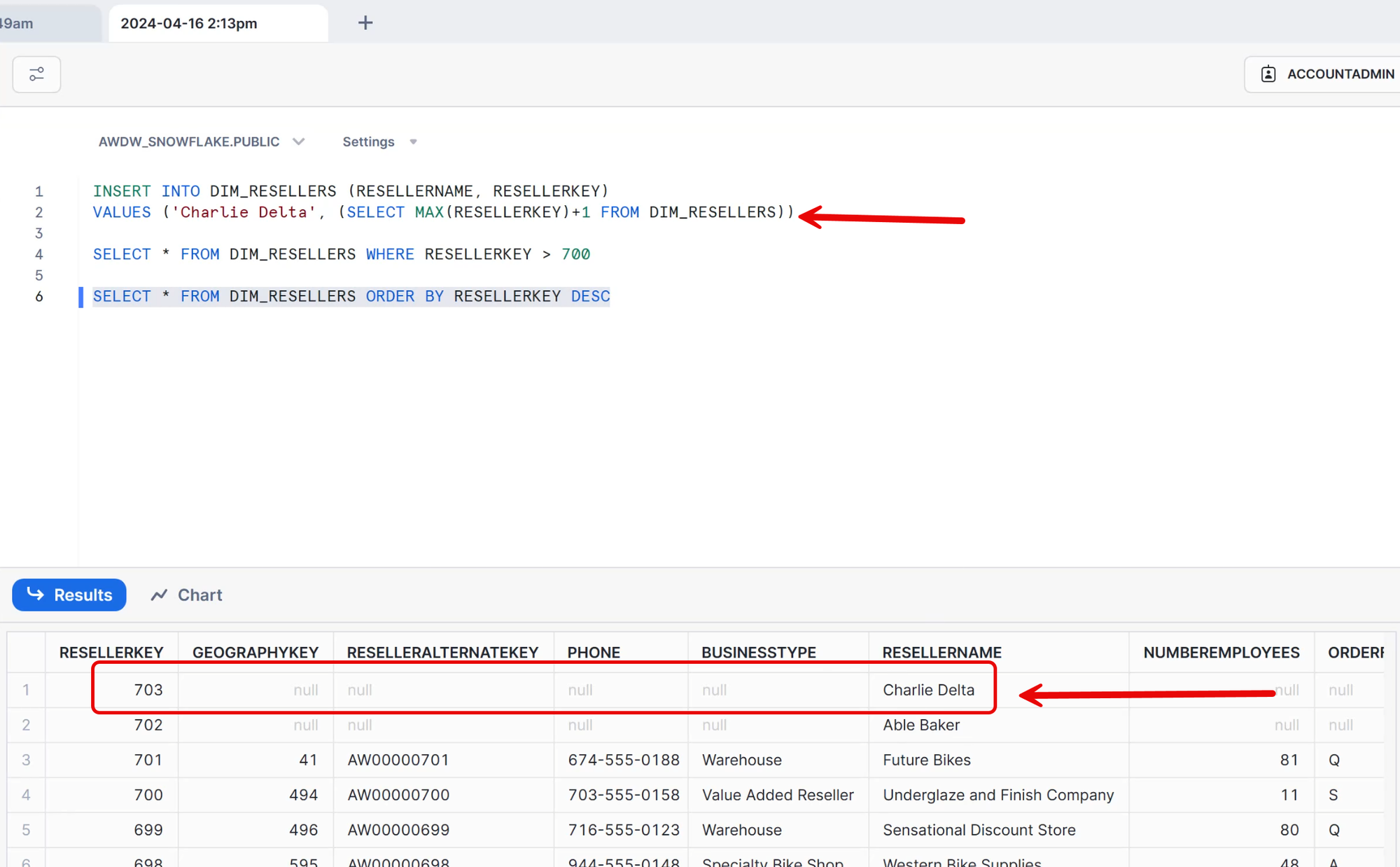
Then, returning to the Fabric Data Warehouse, we can see that the new row was replicated (mirrored) to Fabric almost immediately!
Summary
Snowflake Mirroring provides a way to replicate data in near real-time from a Snowflake data warehouse to a Fabric Data Warehouse.
The Mirrored data in Fabric is stored in Delta Parquet tables, and can be accessed by any Fabric technology, and can be queried via the mirrored data warehouse SQL Analytics endpoint.
Mirroring is included in all Fabric SKUs, and Microsoft doesn't charge for compute or storage (within reasonable limits) for mirrored data. However, mirroring may have an impact on Snowflake compute charges.
However, if near real-time updates in Fabric are desired, Mirroring is a straightforward and relatively easy to implement Fabric feature.




